Meeting the Challenges of the C-Level Executive to Board Director Transition
02/Jul/21 17:16
Life is full of transitions. Some are easy. But most are hard, for one reason or another. The good news of that for many transitions, plenty of guidance is available about how to succeed in making it. But it some cases, helpful, practical guidance is still lacking.
From our board consulting and personal experiences, Neil and I are painfully familiar with one of these: The challenge of transitioning from being a C-Level executive to being a board director. In this post, we’ll briefly summarize some of the key lessons we’ve learned.
A famous saying pithily claims that “management is about telling the answers, and governance is about asking the questions.” That’s definitely something to keep in mind, as well as the fact that many new directors (as well as some long serving ones) struggle to make that transition. But there’s more to it than that.
Broadly speaking, various courts have recognized that directors have two or three fundamental fiduciary duties.
The Duty of Loyalty says that directors must at all times act in the best interests of the company, and avoid personal economic conflict.
The Duty of Good Faith is a doctrine emerging out of various court decisions that requires fiduciaries to have subjectively honest and honorable intentions in all professional actions. Whether that is a separate, standalone duty or one that is subsumed under the duty of loyalty is still a matter of debate.
The Duty of Care refers to the principle that in making decisions, directors must act in the same manner as a reasonably prudent person in their position would.
In practice, the Duty of Care can be further disaggregated into seven key activities that boards perform:
(1) Establish the critical goals the organization must achieve to survive and thrive;
(2) Approve a strategy to reach those goals;
(3) Ensure that the allocation of financial and human resources aligns with that strategy;
(4) Hire a CEO to implement that strategy, and regularly evaluate their performance;
(5) Regularly review critical risks to the success of that strategy and the survival of the organization, and ensure they are being adequately managed;
(6) Ensure the timely and accurate reporting of results to stakeholders;
(7) In line with the “prudent man" rule, ensure that directors have received sufficient information and given it due consideration before making any decision.
In terms of content, C-Level executives transitioning to board directorship are already quite familiar with most of these. As noted above, the main challenge in these cases is developing a constructive Socratic approach -- learning to ask the questions rather than tell the answers.
However, in our experience there are two areas that can be a source of confusion and consternation.
Most C-Level executives tend to think of risk in operational, financial, regulatory, and reputational terms – basically, the standard contents of their previous company’s Enterprise Risk Management program. Typically such programs are organized around specific risks, whose probability of occurrence (over a usually undefined time horizon) and potential impact (sometimes netted against the assumed impact of mitigation measures, and sometimes not) are graphically summarized in the familiar two by two “heat map”. In the case of these risks, the board’s focus should be limited to the adequacy of the Enterprise Risk Management program.
The main focus of the board’s attention should be on strategic risks to the survival of the company and the success of its strategy.
There are good reasons for careful board focus in this area, including management compensation incentives that are strongly tied to upside value creation, not avoiding failure; a natural management focus on short term issues in an intensely competitive environment with constant pressure from investors to deliver high returns; and r recognition by many senior managers that their average job-tenure is growing ever-shorter.
This is not a criticism of management teams, who are rationally reacting to the situations and incentives they face. Rather, it highlights why strategic risk governance is a critical, if often underappreciated, board role.
Technically, these are usually not risks at all, in the sense of situations in which the full range of possible outcomes, and their associated probabilities and potential impacts are well understood (and thus can be priced and transferred to other organizations more willing to bear, for a fee, at least part of the company’s exposure to them). Instead, they are true uncertainties.
Governing strategic risk consists of three critical activities: anticipating future threats, assessing emerging threats (including their potential impact, and, critically, the speed at which they are developing), and ensuring that the organization is adapting to them in time.
The latter is similar to the familiar math problem involving the crossing point of two trains that are both accelerating. The first train is the emerging threat; the second is the process of developing and implementing adaptations before threat passes a critical threshold.
The second, potential source of frustration revolves around whether directors have received sufficient information and given it due consideration before making any decision.
C-Level executives know that sometimes decisions must be made under time pressure, in the face of uncertainty, with less than perfect information. Unlike management decisions, however, board decisions are subject to shareholder litigation (and sometimes regulatory review). It is for this reason that boards often retain independent outside advisors, such as investment banks in the case of mergers, acquisitions, and buyouts.
C-Level executives transitioning to directorship almost always have a strong track record of making good judgments in the face of uncertainty. For this reason, the need to think about information adequacy, alternative interpretations of the information at hand, questioning and validating assumptions, and ensuring that the board follows a clear decision process can easily lead to frustration.
Besides content challenges, new board directors may also face a number of process pitfalls that are deeply rooted in our evolutionary past.
At the individual level, we are naturally both overoptimistic and overconfident. Evolution has also predisposed us to choose people with these characteristics as group leaders.
We also unconsciously strive to maintain a coherent view of the world, and consequently pay less attention to, and underweight, bad news and information that does not fit well within our existing mental model of a system or situation. Most people seek information that confirms their beliefs, rather than information that calls them into question. This is accentuated when directors believe things are going well.
At the group level, when the fear center of our brain (the amygdala) is triggered by rising uncertainty or actual loss, our aversion to social isolation spikes, making us much more likely to conform to the views of a group and to resist voicing our concerns and/or sharing private information that conflicts with the dominant group view.
On boards, this tendency is further reinforced when directors come from similar social and educational backgrounds; a significant number of directors have experience in the organization’s sector, which can cause other directors to give excessive deference to their views, even when they are blind to the emergence of non-traditional threats; and/or the CEO has been in her/his role for a long time and harmonious relations exist between the board and the management team.
Last but certainly not least, the relationship between a Non-Executive Chairman (and the board more generally) and the CEO is, as we write in our research paper on this subject (download it here) a critical organizational bearing point on which long-term organizational survival and success rests.
This is another situation in which things that were quite obvious when one was a C-Level executive often cease to be so when one becomes a director.
In an era of unprecedented complexity and uncertainty, in which digitization and network effects are causing more and more industries to display “winner take all” dynamics, effective board governance has never been more important.
People with previous C-Level executive experience are well positioned to provide it. However, before they can make their critical contributions, there are challenges they must first overcome in the “not as easy as it looks” transition process to becoming an effective board director.
From our board consulting and personal experiences, Neil and I are painfully familiar with one of these: The challenge of transitioning from being a C-Level executive to being a board director. In this post, we’ll briefly summarize some of the key lessons we’ve learned.
A famous saying pithily claims that “management is about telling the answers, and governance is about asking the questions.” That’s definitely something to keep in mind, as well as the fact that many new directors (as well as some long serving ones) struggle to make that transition. But there’s more to it than that.
Broadly speaking, various courts have recognized that directors have two or three fundamental fiduciary duties.
The Duty of Loyalty says that directors must at all times act in the best interests of the company, and avoid personal economic conflict.
The Duty of Good Faith is a doctrine emerging out of various court decisions that requires fiduciaries to have subjectively honest and honorable intentions in all professional actions. Whether that is a separate, standalone duty or one that is subsumed under the duty of loyalty is still a matter of debate.
The Duty of Care refers to the principle that in making decisions, directors must act in the same manner as a reasonably prudent person in their position would.
In practice, the Duty of Care can be further disaggregated into seven key activities that boards perform:
(1) Establish the critical goals the organization must achieve to survive and thrive;
(2) Approve a strategy to reach those goals;
(3) Ensure that the allocation of financial and human resources aligns with that strategy;
(4) Hire a CEO to implement that strategy, and regularly evaluate their performance;
(5) Regularly review critical risks to the success of that strategy and the survival of the organization, and ensure they are being adequately managed;
(6) Ensure the timely and accurate reporting of results to stakeholders;
(7) In line with the “prudent man" rule, ensure that directors have received sufficient information and given it due consideration before making any decision.
In terms of content, C-Level executives transitioning to board directorship are already quite familiar with most of these. As noted above, the main challenge in these cases is developing a constructive Socratic approach -- learning to ask the questions rather than tell the answers.
However, in our experience there are two areas that can be a source of confusion and consternation.
Most C-Level executives tend to think of risk in operational, financial, regulatory, and reputational terms – basically, the standard contents of their previous company’s Enterprise Risk Management program. Typically such programs are organized around specific risks, whose probability of occurrence (over a usually undefined time horizon) and potential impact (sometimes netted against the assumed impact of mitigation measures, and sometimes not) are graphically summarized in the familiar two by two “heat map”. In the case of these risks, the board’s focus should be limited to the adequacy of the Enterprise Risk Management program.
The main focus of the board’s attention should be on strategic risks to the survival of the company and the success of its strategy.
There are good reasons for careful board focus in this area, including management compensation incentives that are strongly tied to upside value creation, not avoiding failure; a natural management focus on short term issues in an intensely competitive environment with constant pressure from investors to deliver high returns; and r recognition by many senior managers that their average job-tenure is growing ever-shorter.
This is not a criticism of management teams, who are rationally reacting to the situations and incentives they face. Rather, it highlights why strategic risk governance is a critical, if often underappreciated, board role.
Technically, these are usually not risks at all, in the sense of situations in which the full range of possible outcomes, and their associated probabilities and potential impacts are well understood (and thus can be priced and transferred to other organizations more willing to bear, for a fee, at least part of the company’s exposure to them). Instead, they are true uncertainties.
Governing strategic risk consists of three critical activities: anticipating future threats, assessing emerging threats (including their potential impact, and, critically, the speed at which they are developing), and ensuring that the organization is adapting to them in time.
The latter is similar to the familiar math problem involving the crossing point of two trains that are both accelerating. The first train is the emerging threat; the second is the process of developing and implementing adaptations before threat passes a critical threshold.
The second, potential source of frustration revolves around whether directors have received sufficient information and given it due consideration before making any decision.
C-Level executives know that sometimes decisions must be made under time pressure, in the face of uncertainty, with less than perfect information. Unlike management decisions, however, board decisions are subject to shareholder litigation (and sometimes regulatory review). It is for this reason that boards often retain independent outside advisors, such as investment banks in the case of mergers, acquisitions, and buyouts.
C-Level executives transitioning to directorship almost always have a strong track record of making good judgments in the face of uncertainty. For this reason, the need to think about information adequacy, alternative interpretations of the information at hand, questioning and validating assumptions, and ensuring that the board follows a clear decision process can easily lead to frustration.
Besides content challenges, new board directors may also face a number of process pitfalls that are deeply rooted in our evolutionary past.
At the individual level, we are naturally both overoptimistic and overconfident. Evolution has also predisposed us to choose people with these characteristics as group leaders.
We also unconsciously strive to maintain a coherent view of the world, and consequently pay less attention to, and underweight, bad news and information that does not fit well within our existing mental model of a system or situation. Most people seek information that confirms their beliefs, rather than information that calls them into question. This is accentuated when directors believe things are going well.
At the group level, when the fear center of our brain (the amygdala) is triggered by rising uncertainty or actual loss, our aversion to social isolation spikes, making us much more likely to conform to the views of a group and to resist voicing our concerns and/or sharing private information that conflicts with the dominant group view.
On boards, this tendency is further reinforced when directors come from similar social and educational backgrounds; a significant number of directors have experience in the organization’s sector, which can cause other directors to give excessive deference to their views, even when they are blind to the emergence of non-traditional threats; and/or the CEO has been in her/his role for a long time and harmonious relations exist between the board and the management team.
Last but certainly not least, the relationship between a Non-Executive Chairman (and the board more generally) and the CEO is, as we write in our research paper on this subject (download it here) a critical organizational bearing point on which long-term organizational survival and success rests.
This is another situation in which things that were quite obvious when one was a C-Level executive often cease to be so when one becomes a director.
In an era of unprecedented complexity and uncertainty, in which digitization and network effects are causing more and more industries to display “winner take all” dynamics, effective board governance has never been more important.
People with previous C-Level executive experience are well positioned to provide it. However, before they can make their critical contributions, there are challenges they must first overcome in the “not as easy as it looks” transition process to becoming an effective board director.
Comments
COVID Has Laid Bare Too Many Leaders' Lack of Critical Thinking Skills
21/May/21 14:34
One definition of critical thinking is “the use of a rigorous process to reach justifiable inferences.” The actions of various officials during the COVID pandemic have made painfully clear that it is a skill in very short supply.
In the United States, the ongoing debate over when to reopen schools for in-person instruction has put paid to K12 leaders’ frequent claim that they teach students how to think critically.
The battle over school reopening in the United States is a perfect case study.
Example #1: Framing of the reopening issue has ignored basic principles of inductive reasoning
Teachers unions and their supporters have basically demanded that district and state leaders (not to mention parents), “prove to us that it is safe to return to school.” And that is just what most proponents of reopening schools have tried to do.
Unfortunately, this approach runs smack into the so-called “problem of induction”, that was first identified by the philosopher David Hume his “Treatise on Human Nature”, published in 1739: No amount of evidence can ever conclusively prove that a hypothesis is true.
To be sure, there are techniques available for systematically weighing evidence to adjust your confidence in the likelihood that a hypothesis is true, such as the Baconian, Bayesian, and Dempster-Shafer methods. But I can find no examples of these methods being applied in any district’s debate about reopening schools.
Instead, parents and employers have repeatedly been treated to the ugly spectacle of both sides of this debate randomly hurling different studies at each other, without any attempt to systematically weigh the evidence they provide.
Nor up until recently have we seen any attempts to use Karl Popper’s approach to avoiding Hume’s problem of induction: Using evidence to falsify rather than prove a claim.
Fortunately this has begun to change, as more evidence accumulates that schools are not dangerous vectors of COVID transmission.
Example #2: Deductive reasoning has been absent
In response, reopening opponents have made a new claim: That in-person instruction is still not safe because of the prevailing rate of positive COVID tests and/or case numbers in the community surrounding the school district.
This has triggered an endless argument about what the community positive rate means for the safety of in-person instruction.
This argument will never end unless and until the warring parties start to complement induction with deductive reasoning — in this case, actually modeling the multiple factors that affect the level of COVID infection risk in school classrooms.
In addition to assumptions about the relative importance of different infection vectors (surface contact, droplet, and aerosols), and the community infection rate (which drives the probability that a student or adult at a school will be COVID positive and asymptomatic), other factors include the cubic feet of space per person in a classroom, the activity being performed (e.g., singing versus a lecture), the length of time a group is in the classroom, and HVAC system parameters (air changes per hour, percentage of outside air exchanged, type of filters in use, windows open/closed, etc.).
Yet I have yet to see this type of modeling systematically incorporated into state and school district discussions about how to measure and manage reopening risks. Unsurprisingly, it also seems to have been completely ignored by the teachers unions.
In the future, every party making claims and/or decisions about school reopening and COVID risk should have to answer these three questions, which have rarely been asked:
(1) What variables are you using in your model of in-school COVID infection risk?
(2) What assumptions are you making about the values of these variables, and how they interact to determine the level of infection risk?
(3) On what evidence are your assumptions based?
Example #3: Few if any forecast-based claims made during the debate of school reopening have been accompanied by estimates of the degree of uncertainty associated with them
Broadly speaking, there are four categories of uncertainty associated with any forecast.
First, there is uncertainty arising from the applicability of a given theory to the situation at hand.
For example, initial forecasts for the spread of COVID were based on the standard “Susceptible – Infected – Recovered” or “SIR” model of infectious disease epidemics. This model assumed that a homogenous population of agents would randomly encounter each other. With some probability, encounters between infected and non-infected agents would produce more infections. Some percentage of infected agents would die, and some would recover, and thereafter become immune to additional infection.
As it has turned out, the standard model’s assumptions did not match the reality of the COVID epidemic. For example, the population was not homogenous – some had characteristics (like age) and conditions (like asthma, obesity) that made them much more likely to become infected and die. Nor were encounters between infected and non-infected agents random – different people followed different patterns -- like riding the subway each day – that created higher and lower risks of infection, or infecting others (i.e., the impact of “superspreaders”). Finally, in the case of COVID, surviving infection did not make people immune to future infections (e.g., with a new variant of SARS-CoV-2) or infecting others.
Second, there is uncertainty associated with the way a theory is translated into a quantitative forecasting model. In the case of COVID, one of the challenges was how to model the impact of lockdowns and varying rates of compliance with them.
Third, there is uncertainty about what values to put on various parameters contained in a model – for example, to take into account the range of possible impacts that superspreaders could have.
Fourth, there is uncertainty associated with the possible presence of calculation errors within the model, particularly in light of research that has found that a substantial number of models have them (this is why more and more organizations now have separate Model Validation and Verification teams).
Example #4: Authorities’ decision processes have not clearly defined, acknowledged, and systematically traded off different parties’ competing goals.
The Wharton School at the University of Pennsylvania has produced an eye-opening economic analysis of the school reopening issue, modeling both students lost lifetime earnings due to school closure and the cost of COVID infection risk, using the same type of “statistical value of a life” used in other public risk analyses (e.g., of the costs and benefits of raising speed limits).
This analysis finds that, assuming minimal learning versus in-classroom instruction and no-recovery of learning losses, students lose between $12,000 and $15,000 in lifetime earnings for each month that schools remain closed.
To be conservative, let’s assume that due to somewhat effective remote instruction and recovery of learning losses, the average earnings hit is “only” $6,000 per month, and that schools “only” remain closed for nine months (three in the spring of 2020, and six during this school year). In a district of 25,000 students, the economic cost of unrecovered student learning losses is $1.4 billion. You read that right: $1.4 billion.
And that doesn’t include the cost of job losses (usually by mothers) caused by extended period of remote learning.
Given the high cost to students, the Wharton team concluded that it only makes sense to continue remote learning if in-person instruction would plausibly cause .355 new community COVID cases per student. And there is no evidence that this is the case.
However, I have yet to hear this long-term cost to students or this tradeoff mentioned in leaders’ discussions about returning to in-person instruction.
Instead, I’ve seen teachers unions opposed to returning to in-person instruction roll out the same playbook they routinely use in discussions about tenure and dismissal of poorly performing teachers.
This argument is based on the concept of Type-1 and Type-2 errors when testing a hypothesis. Errors of commission are Type-1 errors, also known as “false alarms.” Errors of omission are Type-2 errors, or “missed alarms.” There is an unavoidable trade-off between them — the more you reduce the likelihood of errors of commission, the more you increase the probability of errors of omission.
Here’s a real life example: If you incorrectly identify a teacher as poorly performing and dismiss them, you have made an error of commission. If you incorrectly fail to identify a poorly performing teacher and therefore fail to dismiss them, you have committed an error of omission.
Unfortunately, the cost of these two errors is highly asymmetrical. Teachers unions claim tenure is necessary to minimize the chance of errors of commission — wrongfully dismissing a teacher who is not poorly performing. They completely neglect the cost of the corresponding increase in the probability of errors of omission — failing to dismiss poor performers.
As Chetty, Friedman, and Rockhoff found in “Measuring the Impacts of Teachers”, this cost is extremely high — each student suffers an estimated lifetime earnings loss of $52,000. Assuming the poor teacher has a class of 25 students each year for 30 years, the total cost is $39 million.
We face the same tradeoff between errors of commission and omission in the school reopening decision. But yet again, we are failing to think critically about it, by explicitly discussing different parties’ competing goals, and how politicians and district leaders should weigh them in their decision process.
To reduce the probability of errors of commission (teachers becoming infected with COVID in school), teachers unions are refusing to return to in-person instruction until the risk of infection has effectively been eliminated. In turn, they expect students, parents, employers, and society to bear the burden of the far higher cost of the corresponding error of omission: failing to return to school when it was safe to do so. This cost is plausibly estimated to run into the high billions, if not trillions on the national level.
The predictable response of some who read this third critique of their lack of critical thinking is to once again toss critical thinking aside, and implausibly deny that students’ learning losses exist, or claim that they will easily be recovered.
Example #5: District decision makers have also fallen into other “wicked problem” traps
Dr. Anne-Marie Grisogono recently retired from the Australia Department of Defence’s Science and Technology Organization. She is one of the world’s leading experts on complex adaptive systems and the wicked problems that emerge from them.
Wicked problems are “characterized by multiple interdependent goals that are often poorly framed, unrealistic or conflicted, vague or not explicitly stated. Moreover, stakeholders will often disagree on the weights to place on the different goals, or change their minds.” When the pandemic arrived, leaders faced a classic wicked problem.
In a paper published last year (“How Could Future AI Help Tackle Global Complex Problems?") Grisogono described the traps that decision makers usually fall into when struggling with a wicked problem.
These will surprise nobody who has watched most school district decision makers during the pandemic.
One trap is structuring a complex decision process such that nobody involved is responsible for explicitly trading off competing goals Put differently, the buck stops at nobody’s desk. In the case of COVID, we have repeatedly seen health officials make decisions (e.g., imposing lockdowns) based solely on minimizing the risk of infections, without regard to associated economic, mental health, and student learning losses involved.
Grisogono describes other traps that have also been much in evidence during the COVID pandemic.
“Low ambiguity tolerance was found to be a significant factor in precipitating the behavior of prematurely jumping to conclusions about the nature of the problem and what was to be done about it, despite considerable uncertainty…
“The chosen (usually ineffective) course of action was then defended and persevered due to a combination of confirmation bias, commitment bias, and loss aversion, in spite of accumulating contradictory evidence.
“The unfolding disaster was compounded by a number of other reasoning shortcomings such as difficulties in steering processes with long time delays and in projecting cumulative and non-linear processes.”
Conclusion
As I said at the beginning of this post, one definition of critical thinking is “the use of a rigorous process to reach justifiable inferences.”
Unfortunately, there is abundant and damning evidence that critical thinking has been notable by its absence among too many leaders who have been making critical decisions in the fact of complexity, uncertainty, and time pressure during the course of the COVID pandemic. And millions of people have paid the price.
In the United States, the ongoing debate over when to reopen schools for in-person instruction has put paid to K12 leaders’ frequent claim that they teach students how to think critically.
The battle over school reopening in the United States is a perfect case study.
Example #1: Framing of the reopening issue has ignored basic principles of inductive reasoning
Teachers unions and their supporters have basically demanded that district and state leaders (not to mention parents), “prove to us that it is safe to return to school.” And that is just what most proponents of reopening schools have tried to do.
Unfortunately, this approach runs smack into the so-called “problem of induction”, that was first identified by the philosopher David Hume his “Treatise on Human Nature”, published in 1739: No amount of evidence can ever conclusively prove that a hypothesis is true.
To be sure, there are techniques available for systematically weighing evidence to adjust your confidence in the likelihood that a hypothesis is true, such as the Baconian, Bayesian, and Dempster-Shafer methods. But I can find no examples of these methods being applied in any district’s debate about reopening schools.
Instead, parents and employers have repeatedly been treated to the ugly spectacle of both sides of this debate randomly hurling different studies at each other, without any attempt to systematically weigh the evidence they provide.
Nor up until recently have we seen any attempts to use Karl Popper’s approach to avoiding Hume’s problem of induction: Using evidence to falsify rather than prove a claim.
Fortunately this has begun to change, as more evidence accumulates that schools are not dangerous vectors of COVID transmission.
Example #2: Deductive reasoning has been absent
In response, reopening opponents have made a new claim: That in-person instruction is still not safe because of the prevailing rate of positive COVID tests and/or case numbers in the community surrounding the school district.
This has triggered an endless argument about what the community positive rate means for the safety of in-person instruction.
This argument will never end unless and until the warring parties start to complement induction with deductive reasoning — in this case, actually modeling the multiple factors that affect the level of COVID infection risk in school classrooms.
In addition to assumptions about the relative importance of different infection vectors (surface contact, droplet, and aerosols), and the community infection rate (which drives the probability that a student or adult at a school will be COVID positive and asymptomatic), other factors include the cubic feet of space per person in a classroom, the activity being performed (e.g., singing versus a lecture), the length of time a group is in the classroom, and HVAC system parameters (air changes per hour, percentage of outside air exchanged, type of filters in use, windows open/closed, etc.).
Yet I have yet to see this type of modeling systematically incorporated into state and school district discussions about how to measure and manage reopening risks. Unsurprisingly, it also seems to have been completely ignored by the teachers unions.
In the future, every party making claims and/or decisions about school reopening and COVID risk should have to answer these three questions, which have rarely been asked:
(1) What variables are you using in your model of in-school COVID infection risk?
(2) What assumptions are you making about the values of these variables, and how they interact to determine the level of infection risk?
(3) On what evidence are your assumptions based?
Example #3: Few if any forecast-based claims made during the debate of school reopening have been accompanied by estimates of the degree of uncertainty associated with them
Broadly speaking, there are four categories of uncertainty associated with any forecast.
First, there is uncertainty arising from the applicability of a given theory to the situation at hand.
For example, initial forecasts for the spread of COVID were based on the standard “Susceptible – Infected – Recovered” or “SIR” model of infectious disease epidemics. This model assumed that a homogenous population of agents would randomly encounter each other. With some probability, encounters between infected and non-infected agents would produce more infections. Some percentage of infected agents would die, and some would recover, and thereafter become immune to additional infection.
As it has turned out, the standard model’s assumptions did not match the reality of the COVID epidemic. For example, the population was not homogenous – some had characteristics (like age) and conditions (like asthma, obesity) that made them much more likely to become infected and die. Nor were encounters between infected and non-infected agents random – different people followed different patterns -- like riding the subway each day – that created higher and lower risks of infection, or infecting others (i.e., the impact of “superspreaders”). Finally, in the case of COVID, surviving infection did not make people immune to future infections (e.g., with a new variant of SARS-CoV-2) or infecting others.
Second, there is uncertainty associated with the way a theory is translated into a quantitative forecasting model. In the case of COVID, one of the challenges was how to model the impact of lockdowns and varying rates of compliance with them.
Third, there is uncertainty about what values to put on various parameters contained in a model – for example, to take into account the range of possible impacts that superspreaders could have.
Fourth, there is uncertainty associated with the possible presence of calculation errors within the model, particularly in light of research that has found that a substantial number of models have them (this is why more and more organizations now have separate Model Validation and Verification teams).
Example #4: Authorities’ decision processes have not clearly defined, acknowledged, and systematically traded off different parties’ competing goals.
The Wharton School at the University of Pennsylvania has produced an eye-opening economic analysis of the school reopening issue, modeling both students lost lifetime earnings due to school closure and the cost of COVID infection risk, using the same type of “statistical value of a life” used in other public risk analyses (e.g., of the costs and benefits of raising speed limits).
This analysis finds that, assuming minimal learning versus in-classroom instruction and no-recovery of learning losses, students lose between $12,000 and $15,000 in lifetime earnings for each month that schools remain closed.
To be conservative, let’s assume that due to somewhat effective remote instruction and recovery of learning losses, the average earnings hit is “only” $6,000 per month, and that schools “only” remain closed for nine months (three in the spring of 2020, and six during this school year). In a district of 25,000 students, the economic cost of unrecovered student learning losses is $1.4 billion. You read that right: $1.4 billion.
And that doesn’t include the cost of job losses (usually by mothers) caused by extended period of remote learning.
Given the high cost to students, the Wharton team concluded that it only makes sense to continue remote learning if in-person instruction would plausibly cause .355 new community COVID cases per student. And there is no evidence that this is the case.
However, I have yet to hear this long-term cost to students or this tradeoff mentioned in leaders’ discussions about returning to in-person instruction.
Instead, I’ve seen teachers unions opposed to returning to in-person instruction roll out the same playbook they routinely use in discussions about tenure and dismissal of poorly performing teachers.
This argument is based on the concept of Type-1 and Type-2 errors when testing a hypothesis. Errors of commission are Type-1 errors, also known as “false alarms.” Errors of omission are Type-2 errors, or “missed alarms.” There is an unavoidable trade-off between them — the more you reduce the likelihood of errors of commission, the more you increase the probability of errors of omission.
Here’s a real life example: If you incorrectly identify a teacher as poorly performing and dismiss them, you have made an error of commission. If you incorrectly fail to identify a poorly performing teacher and therefore fail to dismiss them, you have committed an error of omission.
Unfortunately, the cost of these two errors is highly asymmetrical. Teachers unions claim tenure is necessary to minimize the chance of errors of commission — wrongfully dismissing a teacher who is not poorly performing. They completely neglect the cost of the corresponding increase in the probability of errors of omission — failing to dismiss poor performers.
As Chetty, Friedman, and Rockhoff found in “Measuring the Impacts of Teachers”, this cost is extremely high — each student suffers an estimated lifetime earnings loss of $52,000. Assuming the poor teacher has a class of 25 students each year for 30 years, the total cost is $39 million.
We face the same tradeoff between errors of commission and omission in the school reopening decision. But yet again, we are failing to think critically about it, by explicitly discussing different parties’ competing goals, and how politicians and district leaders should weigh them in their decision process.
To reduce the probability of errors of commission (teachers becoming infected with COVID in school), teachers unions are refusing to return to in-person instruction until the risk of infection has effectively been eliminated. In turn, they expect students, parents, employers, and society to bear the burden of the far higher cost of the corresponding error of omission: failing to return to school when it was safe to do so. This cost is plausibly estimated to run into the high billions, if not trillions on the national level.
The predictable response of some who read this third critique of their lack of critical thinking is to once again toss critical thinking aside, and implausibly deny that students’ learning losses exist, or claim that they will easily be recovered.
Example #5: District decision makers have also fallen into other “wicked problem” traps
Dr. Anne-Marie Grisogono recently retired from the Australia Department of Defence’s Science and Technology Organization. She is one of the world’s leading experts on complex adaptive systems and the wicked problems that emerge from them.
Wicked problems are “characterized by multiple interdependent goals that are often poorly framed, unrealistic or conflicted, vague or not explicitly stated. Moreover, stakeholders will often disagree on the weights to place on the different goals, or change their minds.” When the pandemic arrived, leaders faced a classic wicked problem.
In a paper published last year (“How Could Future AI Help Tackle Global Complex Problems?") Grisogono described the traps that decision makers usually fall into when struggling with a wicked problem.
These will surprise nobody who has watched most school district decision makers during the pandemic.
One trap is structuring a complex decision process such that nobody involved is responsible for explicitly trading off competing goals Put differently, the buck stops at nobody’s desk. In the case of COVID, we have repeatedly seen health officials make decisions (e.g., imposing lockdowns) based solely on minimizing the risk of infections, without regard to associated economic, mental health, and student learning losses involved.
Grisogono describes other traps that have also been much in evidence during the COVID pandemic.
“Low ambiguity tolerance was found to be a significant factor in precipitating the behavior of prematurely jumping to conclusions about the nature of the problem and what was to be done about it, despite considerable uncertainty…
“The chosen (usually ineffective) course of action was then defended and persevered due to a combination of confirmation bias, commitment bias, and loss aversion, in spite of accumulating contradictory evidence.
“The unfolding disaster was compounded by a number of other reasoning shortcomings such as difficulties in steering processes with long time delays and in projecting cumulative and non-linear processes.”
Conclusion
As I said at the beginning of this post, one definition of critical thinking is “the use of a rigorous process to reach justifiable inferences.”
Unfortunately, there is abundant and damning evidence that critical thinking has been notable by its absence among too many leaders who have been making critical decisions in the fact of complexity, uncertainty, and time pressure during the course of the COVID pandemic. And millions of people have paid the price.
The BIN Model of Forecasting Errors and Its Implications for Improving Predictive Accuracy
08/Apr/21 07:52
At Britten Coyne Partners, Index Investor, and the Strategic Risk Institute, we all share a common mission: To help clients avoid failure by better anticipating, more accurately assessing, and adapting in time to emerging strategic threats.
Improving clients’ (and our own) forecasting process to increase predictive accuracy is critical to our mission and our research in this area is ongoing. In this note, we’ll review a very interesting new paper that has the potential to significantly improve forecast accuracy.
In “Bias, Information, Noise: The BIN Model of Forecasting”, Satopaa, Salikhov, Tetlock, and Mellers introduce a new approach to rigorously assessing the impact of three root causes of forecasting errors. In so doing, they create the opportunity for individuals and organizations to take more carefully targeted actions to improve the predictive accuracy of their forecasts.
In the paper, Satopaa et al decompose forecast errors into three parts, based on the impact of bias, partial information, and noise. They assume that, “forecasters sample and interpret signals with varying skill and thoroughness. They may sample relevant signals (increasing partial information) or irrelevant signals (creating noise). Furthermore, they may center the signals incorrectly (creating bias).”
Let’s start by taking a closer look at each root cause.
WHAT IS BIAS?
A bias is a systematic error that reduces forecast accuracy in a predictable way. Researchers have extensively studied biases and many of them have become well known. Here are some examples:
Over-Optimism: Tali Sharot’s research has shown how humans have a natural bias towards optimism. We are much more prone to updating our beliefs when a new piece of information is positive (i.e., better than expected in light of our goals) rather than negative (“How Unrealistic Optimism is Maintained in the Face of Reality”).
Confirmation: We tend to seek, pay more attention to, and place more weight on information that supports our current beliefs than information that is inconsistent with or contradicts them (this is also known as “my-side” bias).
Social Ranking: Another bias that is deeply rooted in our evolutionary past is the predictable impact of competition for status within a group. Researchers have found that when the result of a decision will be private (not observed by others), we tend to be risk averse. But when the result will be observed, we tend to be risk seeking (e.g., “Interdependent Utilities: How Social Ranking Affects Choice Behavior” by Bault et al).
Social Conformity: Another evolutionary instinct comes into play when uncertainty is high. Under this condition, we are much more likely to rely on social learning and copying the behavior of other group members, and to put less emphasis on any private information we have that is inconsistent with or contradicts the group’s dominant view. The evolutionary basis for this heightened conformity is clear – you don’t want to be cast out of your group when uncertainty is high.
Overconfidence/Uncertainty Neglect: The over-optimism, confirmation, social ranking, and social conformity biases all contribute to forecasters’ systematic neglect of when we make and communicate forecasts. We described this bias (and how to overcome it) much more detail in our February blog post, “How to Effectively Communicate Forecast Probability and Analytic Confidence”.
Surprise Neglect: While less well known than many other biases, this one is, in our experience, one of the most important. Surprise is a critically important feeling that is triggered when our conscious or unconscious attention is attracted to something that violates our expectations of how the world should behave, given our mental model of the phenomenon in question (e.g., stock market valuations increasing when macroeconomic conditions appear to be getting worse). From an evolutionary perspective, surprise helps humans to survive by forcing them to revise their mental models in order to more accurately perceive the world – especially its unexpected dangers and opportunities. Unfortunately, the feeling of surprise is often fleeting.
As Daniel Kahneman noted in his book, “Thinking Fast and Slow”, when confronted with surprise, our automatic, subconscious reasoning system (“System 1”) will quickly attempt to adjust our beliefs to eliminate the feeling. It is only when the adjustment is too big that our conscious reasoning system (“System 2”) is triggered to examine its cause us to feel surprised – but even then, System 1 will still keep trying to make the feeling of surprise disappear. Surprise neglect is one of the most underappreciated reasons that inaccurate mental models tend to persist.
WHAT IS PARTIAL INFORMATION?
In the context of the BIN Model, “information” refers to the extent to which we have complete (and accurate) information about the process generating the future results we seek to forecast.
For example, when a fair coin is flipped four times, we have complete information that enables us to predict the probability of different outcomes with complete confidence. This is the realm of decision in the face of risk.
When the complexity of the results generating process increases, we move from the realm of risk into the realm of uncertainty, in which we often do not fully understand the full range of possible outcomes, their probabilities, or their consequences.
Under these circumstances, forecasters have varying degrees of information about the process generating future results, and/or models of varying degrees of accuracy for interpreting the meaning of the information they have. Both contribute to forecast inaccuracy.
WHAT IS NOISE?
“Noise” is unsystematic, unpredictable, random errors that contribute to forecast inaccuracy. Kahneman defines it as “the chance variability of judgments.”
Sources of noise that are external to forecasters include randomness in the results generating process itself (and, as in the case of complex adaptive systems, the deliberate actions of the intelligent agents who comprise that process). Internal sources of noise include forecasters’ use of low or no value information about and/or a model of a results generating process that are either inaccurate or irrelevant, or that vary over time (often unconsciously).
After applying their analytical “BIN” framework to the results of the Good Judgment Project (a four-year geopolitical forecasting tournament described in the book “Superforecasting” in which one of us participated), Satopaa and his co-authors conclude that, “forecasters fall short of perfect forecasting [accuracy] due more to noise than bias or lack of information. Eliminating noise would reduce forecast errors … by roughly 50%; eliminating bias would yield a roughly 25% cut; [and] increasing information would account for the remaining 25%. In sum, from a variety of analytical angles, reducing noise is roughly twice as effective as reducing bias or increasing information.”
Moreover, they authors found that a variety of interventions used by the Good Judgment Project that were intended to reduce forecaster bias (such as training and teaming) actually had their biggest impact on reducing noise. They note that, “reducing bias may be harder than reducing noise due to the tenacious nature of certain cognitive biases” (a point also made by Kahneman in his Harvard Business Review article, “Noise: How to Overcome the High, Hidden Cost of Inconsistent Decision Making”).
The BIN model highlights three levers for improving forecast accuracy: Reducing Bias, Improving Information, and Reducing Noise. Let’s look at some effective techniques in each of these areas.
HOW TO REDUCE BIAS
The first point to make about bias reduction is that a considerable body of research has concluded that this is very difficult to do, for the simple reason that deep in our evolutionary past, what we negatively refer to as “biases” served a positive evolutionary purpose (e.g., overconfidence helped to attract mates).
That said, both our experience with Britten Coyne Partners’ clients and academic research has found that two techniques are often effective.
Reference/Base Rates and Shrinkage: Too often we behave as if the only information that matters is what we know about the question or results we are trying to forecast. We fail to take into account how things have turned out in similar cases in the past (this is know as the reference or base rate). So-called “shrinkage” methods start by identifying a relevant base rate for the forecast, then move on to developing a forecast based on the specific situation under consideration. The more similar the specific situation is to the ones used to calculate the base rate, the more the specific probability is “shrunk” towards the base rate probability.
Pre-Mortem Analysis: Popularized by Gary Klein, in a pre-mortem a team is told to assume that it is some point in the future, and a forecast (or plan) has failed. They are told to anonymously write down the causes of the failure, including critical signals that were missed, and what could have been done differently to increase the probability of success. Pre-mortems reduce over-optimism and overconfidence, and produce two critical outputs: improvement in forecasts and plans, and the identification of critical uncertainties about which more information needs to be collected as the future unfolds (which improves signal quality). The power of pre-mortems is due to the fact that humans have a much easier time (and are much more detailed) in explaining the past than they are when asked to forecast the future – hence the importance of situating a group in the future, and asking them to explain a past that has yet to occur.
HOW TO INCREASE RELEVANT INFORMATION (SIGNAL)?
Hyperconnectivity has unleashed upon us a daily flood of information with which many people are unable to cope when they have to make critical decisions (and forecasts) in the face of uncertainty. Two approaches can help.
Information Value Analysis: Bayes Theory provides a method for separating high value signals from the flood of noise that accompanies them. Let’s say that you have determined that three outcomes (A, B, and C) are possible. The value of a new piece of information (or related pieces of evidence) can be determined based on the likelihood you would observe it if Outcomes A, B, or C happen. If the information is much more likely to be observed in the case of just one outcome, it has high value. If it is equally likely under all three outcomes, it has no value. More difficult, but just as informative, is applying this same logic to the absence of a piece of information. This analysis (and the outcome probability estimates) should be repeated at regular intervals to assess newly arriving evidence.
Assumptions Analysis: Probabilistic forecasts rest on a combination of (1) facts, (2) assumptions about critical uncertainties, (3) the evidence (of varying reliability and information value) supporting those assumptions, and (4) the logic used to reach the forecaster’s conclusion. In our forecasting work with clients over the years, we have found that discussing the assumptions made about critical uncertainties, and, less frequently the forecast logic itself, generates very productive discussions and improves predictive accuracy.
In particular, Marvin Cohen’s approach has proved quite practical. His research found that the greater the number of assumptions about “known unknowns” (i.e., recognized uncertainties) that underlie a forecast, and the weaker the evidence that supports them, the lower confidence one should have in the forecast’s accuracy.
Also, the more assumptions about “known unknowns” that are used in a forecast, the more likely it is that potentially critical “unknown unknowns” remain to be discovered, which again should lower your confidence in the forecast (e.g., see, “Metarecognition in Time-Stressed Decision Making: Recognizing, Critiquing, and Correcting” by Cohen, Freeman, and Wolf).
HOW TO REDUCE NOISE?
Combine and Extremize Forecasts: Research has found that three steps can improve forecast accuracy. The first is seeking forecasts based on different forecasting methodologies, or prepared by forecasters with significantly different backgrounds (as a proxy for different mental models and information). The second is combining those forecasts (using a simple average if few are included, or the median if many are). The final step, which significantly improved the performance of the Good Judgment Project team in the IARPA forecasting tournament, is to “extremize” the average (mean) or median forecast by moving it closer to 0% or 100%.
Averaging forecasts assumes that the differences between them are all due to noise. However, as the number of forecasts being combined increases, use of the median produces the greatest increase in accuracy because it does not “average away” all information differences between forecasters. However, that still leaves whatever bias is present in the median forecast.
Forecasts for binary events (e.g., the probability an event will or will not happen within a given time frame) are most useful to decision makers when they are closer to 0% or 100% rather than the uninformative “coin toss” estimate of a 50% probability. As described by Baron et al in “Two Reasons to Make Aggregated Probability Forecasts More Extreme”, individual forecasters will often shrink their probability estimates towards 50% to take into account their subjective belief about the extent of potentially useful information that they are missing.
For this reason, forecast accuracy can usually be increased when you employ a structured “extremizing” technique to move the mean or median probability estimate closer to 0% or 100%. Note that the extremizing factor should be lower when average forecaster expertise is higher. This is based on the assumption that a group of expert forecasters will incorporate more of the full amount of potentially useful information than will novice forecasters. (See: “Two Reasons to Make Aggregated Probability Forecasts More Extreme”, by Baron et al, and “Decomposing the Effects of Crowd-Wisdom Aggregators”, by Satopaa et al).
Use a Forecasting Algorithm: Use of an algorithm (whose structure can be inferred from top human forecasters’ performance) ensures that a forecast’s information inputs and their weighting are consistent over time. In some cases, this approach can be automated; in others, it involves having a group of forecasters (e.g., interviewers of new hire candidates) ask the same set of questions and use the same rating scale, which facilitates the consistent combination of their inputs. Kahneman has also found that testing these algorithmic conclusions against forecasters’ intuition, and then examining the underlying reasons for any disagreements between the results of the two methods can sometimes improve results.
However, it is also critical to note that this algorithmic approach implicitly assumes that the underlying process generating the results being forecast is stable over time. In the case of complex adaptive systems (which are constantly evolving), this is not true.
Unfortunately, many of the critical forecasting challenges we face involve results produced by complex adaptive systems. For the foreseeable future, expert human forecasters will still be needed to meet them. By decomposing the root causes of forecasting error, the BIN model will help them to do that.
Improving clients’ (and our own) forecasting process to increase predictive accuracy is critical to our mission and our research in this area is ongoing. In this note, we’ll review a very interesting new paper that has the potential to significantly improve forecast accuracy.
In “Bias, Information, Noise: The BIN Model of Forecasting”, Satopaa, Salikhov, Tetlock, and Mellers introduce a new approach to rigorously assessing the impact of three root causes of forecasting errors. In so doing, they create the opportunity for individuals and organizations to take more carefully targeted actions to improve the predictive accuracy of their forecasts.
In the paper, Satopaa et al decompose forecast errors into three parts, based on the impact of bias, partial information, and noise. They assume that, “forecasters sample and interpret signals with varying skill and thoroughness. They may sample relevant signals (increasing partial information) or irrelevant signals (creating noise). Furthermore, they may center the signals incorrectly (creating bias).”
Let’s start by taking a closer look at each root cause.
WHAT IS BIAS?
A bias is a systematic error that reduces forecast accuracy in a predictable way. Researchers have extensively studied biases and many of them have become well known. Here are some examples:
Over-Optimism: Tali Sharot’s research has shown how humans have a natural bias towards optimism. We are much more prone to updating our beliefs when a new piece of information is positive (i.e., better than expected in light of our goals) rather than negative (“How Unrealistic Optimism is Maintained in the Face of Reality”).
Confirmation: We tend to seek, pay more attention to, and place more weight on information that supports our current beliefs than information that is inconsistent with or contradicts them (this is also known as “my-side” bias).
Social Ranking: Another bias that is deeply rooted in our evolutionary past is the predictable impact of competition for status within a group. Researchers have found that when the result of a decision will be private (not observed by others), we tend to be risk averse. But when the result will be observed, we tend to be risk seeking (e.g., “Interdependent Utilities: How Social Ranking Affects Choice Behavior” by Bault et al).
Social Conformity: Another evolutionary instinct comes into play when uncertainty is high. Under this condition, we are much more likely to rely on social learning and copying the behavior of other group members, and to put less emphasis on any private information we have that is inconsistent with or contradicts the group’s dominant view. The evolutionary basis for this heightened conformity is clear – you don’t want to be cast out of your group when uncertainty is high.
Overconfidence/Uncertainty Neglect: The over-optimism, confirmation, social ranking, and social conformity biases all contribute to forecasters’ systematic neglect of when we make and communicate forecasts. We described this bias (and how to overcome it) much more detail in our February blog post, “How to Effectively Communicate Forecast Probability and Analytic Confidence”.
Surprise Neglect: While less well known than many other biases, this one is, in our experience, one of the most important. Surprise is a critically important feeling that is triggered when our conscious or unconscious attention is attracted to something that violates our expectations of how the world should behave, given our mental model of the phenomenon in question (e.g., stock market valuations increasing when macroeconomic conditions appear to be getting worse). From an evolutionary perspective, surprise helps humans to survive by forcing them to revise their mental models in order to more accurately perceive the world – especially its unexpected dangers and opportunities. Unfortunately, the feeling of surprise is often fleeting.
As Daniel Kahneman noted in his book, “Thinking Fast and Slow”, when confronted with surprise, our automatic, subconscious reasoning system (“System 1”) will quickly attempt to adjust our beliefs to eliminate the feeling. It is only when the adjustment is too big that our conscious reasoning system (“System 2”) is triggered to examine its cause us to feel surprised – but even then, System 1 will still keep trying to make the feeling of surprise disappear. Surprise neglect is one of the most underappreciated reasons that inaccurate mental models tend to persist.
WHAT IS PARTIAL INFORMATION?
In the context of the BIN Model, “information” refers to the extent to which we have complete (and accurate) information about the process generating the future results we seek to forecast.
For example, when a fair coin is flipped four times, we have complete information that enables us to predict the probability of different outcomes with complete confidence. This is the realm of decision in the face of risk.
When the complexity of the results generating process increases, we move from the realm of risk into the realm of uncertainty, in which we often do not fully understand the full range of possible outcomes, their probabilities, or their consequences.
Under these circumstances, forecasters have varying degrees of information about the process generating future results, and/or models of varying degrees of accuracy for interpreting the meaning of the information they have. Both contribute to forecast inaccuracy.
WHAT IS NOISE?
“Noise” is unsystematic, unpredictable, random errors that contribute to forecast inaccuracy. Kahneman defines it as “the chance variability of judgments.”
Sources of noise that are external to forecasters include randomness in the results generating process itself (and, as in the case of complex adaptive systems, the deliberate actions of the intelligent agents who comprise that process). Internal sources of noise include forecasters’ use of low or no value information about and/or a model of a results generating process that are either inaccurate or irrelevant, or that vary over time (often unconsciously).
After applying their analytical “BIN” framework to the results of the Good Judgment Project (a four-year geopolitical forecasting tournament described in the book “Superforecasting” in which one of us participated), Satopaa and his co-authors conclude that, “forecasters fall short of perfect forecasting [accuracy] due more to noise than bias or lack of information. Eliminating noise would reduce forecast errors … by roughly 50%; eliminating bias would yield a roughly 25% cut; [and] increasing information would account for the remaining 25%. In sum, from a variety of analytical angles, reducing noise is roughly twice as effective as reducing bias or increasing information.”
Moreover, they authors found that a variety of interventions used by the Good Judgment Project that were intended to reduce forecaster bias (such as training and teaming) actually had their biggest impact on reducing noise. They note that, “reducing bias may be harder than reducing noise due to the tenacious nature of certain cognitive biases” (a point also made by Kahneman in his Harvard Business Review article, “Noise: How to Overcome the High, Hidden Cost of Inconsistent Decision Making”).
The BIN model highlights three levers for improving forecast accuracy: Reducing Bias, Improving Information, and Reducing Noise. Let’s look at some effective techniques in each of these areas.
HOW TO REDUCE BIAS
The first point to make about bias reduction is that a considerable body of research has concluded that this is very difficult to do, for the simple reason that deep in our evolutionary past, what we negatively refer to as “biases” served a positive evolutionary purpose (e.g., overconfidence helped to attract mates).
That said, both our experience with Britten Coyne Partners’ clients and academic research has found that two techniques are often effective.
Reference/Base Rates and Shrinkage: Too often we behave as if the only information that matters is what we know about the question or results we are trying to forecast. We fail to take into account how things have turned out in similar cases in the past (this is know as the reference or base rate). So-called “shrinkage” methods start by identifying a relevant base rate for the forecast, then move on to developing a forecast based on the specific situation under consideration. The more similar the specific situation is to the ones used to calculate the base rate, the more the specific probability is “shrunk” towards the base rate probability.
Pre-Mortem Analysis: Popularized by Gary Klein, in a pre-mortem a team is told to assume that it is some point in the future, and a forecast (or plan) has failed. They are told to anonymously write down the causes of the failure, including critical signals that were missed, and what could have been done differently to increase the probability of success. Pre-mortems reduce over-optimism and overconfidence, and produce two critical outputs: improvement in forecasts and plans, and the identification of critical uncertainties about which more information needs to be collected as the future unfolds (which improves signal quality). The power of pre-mortems is due to the fact that humans have a much easier time (and are much more detailed) in explaining the past than they are when asked to forecast the future – hence the importance of situating a group in the future, and asking them to explain a past that has yet to occur.
HOW TO INCREASE RELEVANT INFORMATION (SIGNAL)?
Hyperconnectivity has unleashed upon us a daily flood of information with which many people are unable to cope when they have to make critical decisions (and forecasts) in the face of uncertainty. Two approaches can help.
Information Value Analysis: Bayes Theory provides a method for separating high value signals from the flood of noise that accompanies them. Let’s say that you have determined that three outcomes (A, B, and C) are possible. The value of a new piece of information (or related pieces of evidence) can be determined based on the likelihood you would observe it if Outcomes A, B, or C happen. If the information is much more likely to be observed in the case of just one outcome, it has high value. If it is equally likely under all three outcomes, it has no value. More difficult, but just as informative, is applying this same logic to the absence of a piece of information. This analysis (and the outcome probability estimates) should be repeated at regular intervals to assess newly arriving evidence.
Assumptions Analysis: Probabilistic forecasts rest on a combination of (1) facts, (2) assumptions about critical uncertainties, (3) the evidence (of varying reliability and information value) supporting those assumptions, and (4) the logic used to reach the forecaster’s conclusion. In our forecasting work with clients over the years, we have found that discussing the assumptions made about critical uncertainties, and, less frequently the forecast logic itself, generates very productive discussions and improves predictive accuracy.
In particular, Marvin Cohen’s approach has proved quite practical. His research found that the greater the number of assumptions about “known unknowns” (i.e., recognized uncertainties) that underlie a forecast, and the weaker the evidence that supports them, the lower confidence one should have in the forecast’s accuracy.
Also, the more assumptions about “known unknowns” that are used in a forecast, the more likely it is that potentially critical “unknown unknowns” remain to be discovered, which again should lower your confidence in the forecast (e.g., see, “Metarecognition in Time-Stressed Decision Making: Recognizing, Critiquing, and Correcting” by Cohen, Freeman, and Wolf).
HOW TO REDUCE NOISE?
Combine and Extremize Forecasts: Research has found that three steps can improve forecast accuracy. The first is seeking forecasts based on different forecasting methodologies, or prepared by forecasters with significantly different backgrounds (as a proxy for different mental models and information). The second is combining those forecasts (using a simple average if few are included, or the median if many are). The final step, which significantly improved the performance of the Good Judgment Project team in the IARPA forecasting tournament, is to “extremize” the average (mean) or median forecast by moving it closer to 0% or 100%.
Averaging forecasts assumes that the differences between them are all due to noise. However, as the number of forecasts being combined increases, use of the median produces the greatest increase in accuracy because it does not “average away” all information differences between forecasters. However, that still leaves whatever bias is present in the median forecast.
Forecasts for binary events (e.g., the probability an event will or will not happen within a given time frame) are most useful to decision makers when they are closer to 0% or 100% rather than the uninformative “coin toss” estimate of a 50% probability. As described by Baron et al in “Two Reasons to Make Aggregated Probability Forecasts More Extreme”, individual forecasters will often shrink their probability estimates towards 50% to take into account their subjective belief about the extent of potentially useful information that they are missing.
For this reason, forecast accuracy can usually be increased when you employ a structured “extremizing” technique to move the mean or median probability estimate closer to 0% or 100%. Note that the extremizing factor should be lower when average forecaster expertise is higher. This is based on the assumption that a group of expert forecasters will incorporate more of the full amount of potentially useful information than will novice forecasters. (See: “Two Reasons to Make Aggregated Probability Forecasts More Extreme”, by Baron et al, and “Decomposing the Effects of Crowd-Wisdom Aggregators”, by Satopaa et al).
Use a Forecasting Algorithm: Use of an algorithm (whose structure can be inferred from top human forecasters’ performance) ensures that a forecast’s information inputs and their weighting are consistent over time. In some cases, this approach can be automated; in others, it involves having a group of forecasters (e.g., interviewers of new hire candidates) ask the same set of questions and use the same rating scale, which facilitates the consistent combination of their inputs. Kahneman has also found that testing these algorithmic conclusions against forecasters’ intuition, and then examining the underlying reasons for any disagreements between the results of the two methods can sometimes improve results.
However, it is also critical to note that this algorithmic approach implicitly assumes that the underlying process generating the results being forecast is stable over time. In the case of complex adaptive systems (which are constantly evolving), this is not true.
Unfortunately, many of the critical forecasting challenges we face involve results produced by complex adaptive systems. For the foreseeable future, expert human forecasters will still be needed to meet them. By decomposing the root causes of forecasting error, the BIN model will help them to do that.
Complexity, Wicked Problems, and AI-Augmented Decision Making
17/Mar/21 13:08
Over the years, some of the most thought provoking research we have read on the practical implications and applications of complex adaptive systems theory has come from people who have never received the recognition their thinking deserves. One is Dietrich Dorner and his team at Otto-Friedrich University in Bamberg, Germany (see his book, “The Logic of Failure”). Another is Anne-Marie Grisogono, who worked for years at Defense Science and Technology Australia and has recently left there for academia, at Flinders University in Adelaide, Australia.
Grisogono recently published “How Could Future AI Help Tackle Global Complex Problems?” It is a great synthesis of the challenges for decision makers posed by increasing complexity and how improving artificial intelligence technologies could one day help meet them.
She begins by noting that, “we can define intelligence as the ability to produce effective responses or courses of action that are solutions to complex problems—in other words, problems that are unlikely to be solved by random trial and error, and that therefore require the abilities to make finer and finer distinctions between more and more combinations of relevant factors and to process them so as to generate a good enough solution.”
Grisogono then links this definition of intelligence to the emergence and growth of complexity. “Obviously [finding good enough solutions] becomes more difficult as the number of possible choices increases, and as the number of relevant factors and the consequence pathways multiply. Thus complexity in the ecosystem environment generates selection pressure for effective adaptive responses to the [increasing] complexity.”
“One possible adaptive strategy is to find niches to specialize for, within which the complexity is reduced. The opposite strategy is to improve the ability to cope with the complexity by evolving increased intelligence at an individual level, or collective intelligence through various types of cooperative or mutualistic relationships. Either way, increased intelligence in one species will generally increase the complexity of the problems they pose for both other species in the shared ecosystem environment, and for their own conspecifics, driving yet further rounds of adaptations. Even when cooperative interactions evolve to deal with problems that are more complex than an individual can cope with, the shared benefits come with a further complexity cost”…
That said, “it is evident that human intelligence and ingenuity have led to immense progress in producing solutions for many of the pressing problems of past generations, such as higher living standards, longer life expectancy, better education and working conditions. But it is equally evident that the transformations they have wrought in human society and in the planetary environment include many harmful unintended consequences, and that the benefits themselves are not equitably distributed and have often masked unexpected downsides…
“This ratcheting dynamic of increasing intelligence and increasing complexity continues as long as two conditions are met: further increases in sensing and processing are sufficiently accessible to the evolutionary process, and the selection pressure is sufficient to drive it. Either condition can fail. Thus generally a plateau of dynamic equilibrium is reached. But it is also possible that under the right conditions, which we will return to below, the ratcheting of both complexity and intelligence may continue and accelerate.”
Grisogono then moves on to a fascinating and admirably succinct discussion of “what we have learned about the specific limitations that plague human decision-makers in complex problems. We can break this down into two parts: the aspects of complex problems that we find so difficult, and what it is about our brains that limits our ability to cope with those aspects.”
She begins by noting that, “Interdependence is a defining feature of complexity and has many challenging and interesting consequences. In particular, the network of interdependencies between different elements of the problem means that it cannot be successfully treated by dividing it into sub-problems that can be handled separately. Any attempt to do that creates more problems than it solves because of the interactions between the partial solutions…
“There is no natural boundary that completely isolates a complex problem from the context it is embedded in. There is always some traffic of information, resources, and agents in and out of the situation that can bring about unexpected changes, and therefore the context cannot be excluded from attention…
“Complex problems exist at multiple scales, with different agents, behaviors and properties at each, but with interactions between scales. This includes emergence, the appearance of complex structure and dynamics at larger scales as a result of smaller-scale phenomena, and its converse, top-down causation, whereby events or properties at a larger scale can alter what is happening at the smaller scales. In general, all the scales are important, and there is no single “right” scale at which to act…
“Interdependence implies multiple interacting causal and influence pathways leading to, and fanning out from, any event or property, so simple causality (one cause—one effect), or linear causal chains will not hold in general. Yet much of our cultural conditioning is predicated on a naïve view of linear causal chains, such as finding “the cause” of an effect, or “the person” to be held responsible for something, or “the cure” for a problem. Focusing on singular or primary causes makes it more difficult to intervene effectively in complex systems and produce desired outcomes without attendant undesired ones—so-called “side-effects” or unintended consequences…
“Furthermore, such networks of interactions between contributing factors can produce emergent behaviors which are not readily attributable or intuitively anticipatable or comprehensible, implying unknown risks and unrecognized opportunities” ...
“Many important aspects of complex problems are hidden, so there is inevitable uncertainty as to how the events and properties that are observable, are linked through causal and influence pathways, and therefore many hypotheses about them are possible. These cannot be easily distinguished based on the available evidence…
As if complexity isn’t enough, “there are generally multiple interdependent goals in a complex problem, both positive and negative, poorly framed, often unrealistic or conflicted, vague or not explicitly stated, and stakeholders will often disagree on the weights to place on the different goals, or change their minds. Achieving sufficient high level goal clarity to develop concrete goals for action is in itself a complex problem…
Grisogono then summarizes the cognitive abilities that are needed to successfully engage with complex problems.
“One immediate conclusion that can be drawn is that there is a massive requirement for cognitive bandwidth—not only to keep all the relevant aspects at all the relevant scales in mind as one seeks to understand the nature of the problem and what may be possible to do, but even more challenging, to incorporate appropriate non-linear dynamics as trajectories in time are explored…
“But there is a more fundamental problem that needs to be addressed first: how to acquire the necessary relevant information about the composition, structure and dynamics of the complex problem and its context at all the necessary scales, and revise and update it as it evolves. This requires a stance of continuous learning, i.e., simultaneous sensing, testing, learning and updating across all the dimensions and scales of the problem, and the ability to discover and access relevant sources of information. At their best, humans are okay at this, up to a point, but not at the sheer scale and tempo of what is required in real world complex problems which refuse to stand still while we catch up…
“To understand how all these factors interact to limit human competence in managing complex problems, and what opportunities might exist for mitigating them through advanced AI systems, we now review some key findings from relevant research.
“In particular we are interested in learning about the nature of human decision-making in the context of attempting to manage an ongoing situation which is sufficiently protracted and complex to defeat most, but not all, decision-makers.
“Drawing useful conclusions about the detailed decision-making behaviors that tend to either sow the seeds of later catastrophes, or build a basis for sustained success, calls for an extensive body of empirical data from many diverse human subjects making complex decisions in controllable and repeatable complex situations. Clearly this is a tall ask, so not surprisingly, the field is sparse.
"However, one such research program [led by Dietrich Dorner and his team], which has produced important insights about how successful and unsuccessful decision-making behaviors differ, stands out in having also addressed the underlying neurocognitive and affective processes that conspire to make it very difficult for human decision-makers to maintain the more successful behaviors, and to avoid falling into a vicious cycle of less effective behaviors.
“In brief, through years of experimentation with human subjects attempting to achieve complex goals in computer-based micro-worlds with complex underlying dynamics, the specific decision-making behaviors that differentiated a small minority of subjects who achieved acceptable outcomes in the longer term, from the majority who failed to do so, were identified. Results indicated that most subjects could score some quick wins early in the game, but as the unintended consequences of their actions developed and confronted them, and their attempts to deal with them created further problems, the performance of the overwhelming majority (90%) quickly deteriorated, pushing their micro-worlds into catastrophic or chronic failure.
“As would be expected, their detailed behaviors reproduced many well-documented findings about the cognitive traps posed by human heuristics and biases. Low ambiguity tolerance was found to be a significant factor in precipitating the behavior of prematurely jumping to conclusions about the problem and what was to be done about it, when faced with situational uncertainty, ambiguity and pressure to achieve high-level goals. The chosen (usually ineffective) course of action was then defended and persevered with through a combination of confirmation bias, commitment bias, and loss aversion, in spite of available contradictory evidence.
"The unfolding disaster was compounded by a number of other reasoning shortcomings such as difficulties in steering processes with long latencies and in projecting cumulative and non-linear processes. Overall they had poor situation understanding, were likely to focus on symptoms rather than causal factors, were prone to a number of dysfunctional behavior patterns, and attributed their failures to external causes rather than learning from them and taking responsibility for the outcomes they produced.
“By contrast, the remaining ten percent who eventually found ways to stabilize their micro-world, showed systematic differences in their decision-making behaviors and were able to counter the same innate tendencies by taking what amounts to an adaptive approach, developing a conceptual model of the situation, and a stratagem based on causal factors, seeking to learn from unexpected outcomes, and constantly challenging their own thinking and views. Most importantly, they displayed a higher degree of ambiguity tolerance than the unsuccessful majority.
These findings are particularly significant here because most of the individual human decision-making literature has concentrated on how complex decision-making fails, not on how it succeeds. However, insights from research into successful organizational decision-making in complex environments corroborate the importance of taking an adaptive approach.
“In summary, analysis of the effective decision behaviors offers important insights into what is needed, in both human capabilities and AI support, to deal with even higher levels of complexity beyond current human competence. There are two complementary aspects here—put simply: how to avoid pitfalls (what not to do), and how to adopt more successful approaches (what to do instead).
“It is not difficult to understand how the decision making behaviors associated with the majority contributed to their lack of success, nor how those of the rest enabled them to develop sufficient conceptual and practical understanding to manage and guide the situation to an acceptable regime. Indeed if the two lists of behaviors are presented to an audience, everyone can readily identify which list leads to successful outcomes and which leads to failure.
"Yet if those same individuals are placed in the micro-world hot seat, 90% of them will display the very behaviors they just identified as likely to be unsuccessful. This implies that the displayed behaviors are not the result of conscious rational choice, but are driven to some extent by unconscious processes...
“This observation informed development of a theoretical model [by Dorner and his team] incorporating both cognitive and neurophysiological processes to explain the observed data. In brief, the model postulates two basic psychological drives that are particularly relevant to complex decision making, a need for certainty and a need for competence. These are pictured metaphorically as tanks that can be topped up by signals of certainty (one’s expectations being met) and signals of competence (one’s actions producing desired outcomes), and drained by their opposites—surprises and unsuccessful actions.
“The difference between the current level and the set point of a tank creates a powerful unconscious need, stimulating some behavioral tendencies and suppressing others, and impacting on cognitive functions through stimulation of physiological stress. If both levels are sufficient the result is motivation to explore, reflect, seek information and take risky action if necessary—all necessary components of effective decision making behavior.
"But if the levels get too low the individual becomes anxious and is instead driven to flee, look for reassurance from others, seek only information that confirms his existing views so as to top up his dangerously low senses of certainty and competence, and deny or marginalize any tank draining contradictory information…
“The impacts of stress on cognitive functions reinforce these tendencies by reducing abilities to concentrate, sustain a course of action, and recall relevant knowledge. Individuals whose tanks are low therefore find it difficult to sustain the decision-making behaviors associated with success, and are likely to act in ways that generate further draining signals, digging themselves deeper into a vicious cycle of failure.
“We can now understand the 90:10 ratio, as the competing attractors are not symmetric—the vicious cycle of the less effective decision behaviors is self-reinforcing and robust, while the virtuous cycle of success is more fragile because one’s actions are not the sole determinant of outcomes in a complex situation, so even the best decision-makers will sometimes find their tanks getting depleted, and therefore have difficulty sustaining the more effective decision making behaviors.
“Further research has demonstrated that the more effective decision making behaviors are trainable to some extent, but because they entail changing meta-cognitive habits they require considerable practice, reinforcement and ongoing support.
"However, the scope for significant enhancement of unaided human complex decision making competence is limited—not only in the level of competence achievable, but also and more importantly, in the degree of complexity that can be managed. Meanwhile, the requirements for increased competence, and the inexorable rise in degree of complexity to be managed, continue to grow.”
In the remainder of the paper, Grisogono lays out the requirements for an AI system that could substantially improve our ability to make good decisions when confronted with complex, wicked problems. She concludes that current AI technology is far from what we need.
"Despite its successes, the best examples of AI are still very specialized applications that focus on well-defined domains, and that generally require a vast amount of training data to achieve their high performance. Such applications can certainly be components of an AI decision support system for managing very complex problems, but the factors [already] discussed imply that much more is needed: not just depth in narrow aspects, but breadth of scope by connecting the necessary components so as to create a virtual environment which is a sufficiently valid model of the problem and its context, and in which decision-makers can safely explore and test options for robustness and effectiveness, while being supported in maintaining effective decision making behaviors and resisting the less effective ones.”
Until AI-based decision support systems like this are developed, human beings’ batting average in successfully resolving the growing number of wicked problems we face is destined to remain low, and our few successes heavily dependent on a very small set of uniquely talented people who have a superior intuitive grasp of the nature and behavior of complex adaptive systems. In the short-term and medium-term, our critical challenge is how to increase their number.
Grisogono recently published “How Could Future AI Help Tackle Global Complex Problems?” It is a great synthesis of the challenges for decision makers posed by increasing complexity and how improving artificial intelligence technologies could one day help meet them.
She begins by noting that, “we can define intelligence as the ability to produce effective responses or courses of action that are solutions to complex problems—in other words, problems that are unlikely to be solved by random trial and error, and that therefore require the abilities to make finer and finer distinctions between more and more combinations of relevant factors and to process them so as to generate a good enough solution.”
Grisogono then links this definition of intelligence to the emergence and growth of complexity. “Obviously [finding good enough solutions] becomes more difficult as the number of possible choices increases, and as the number of relevant factors and the consequence pathways multiply. Thus complexity in the ecosystem environment generates selection pressure for effective adaptive responses to the [increasing] complexity.”
“One possible adaptive strategy is to find niches to specialize for, within which the complexity is reduced. The opposite strategy is to improve the ability to cope with the complexity by evolving increased intelligence at an individual level, or collective intelligence through various types of cooperative or mutualistic relationships. Either way, increased intelligence in one species will generally increase the complexity of the problems they pose for both other species in the shared ecosystem environment, and for their own conspecifics, driving yet further rounds of adaptations. Even when cooperative interactions evolve to deal with problems that are more complex than an individual can cope with, the shared benefits come with a further complexity cost”…
That said, “it is evident that human intelligence and ingenuity have led to immense progress in producing solutions for many of the pressing problems of past generations, such as higher living standards, longer life expectancy, better education and working conditions. But it is equally evident that the transformations they have wrought in human society and in the planetary environment include many harmful unintended consequences, and that the benefits themselves are not equitably distributed and have often masked unexpected downsides…
“This ratcheting dynamic of increasing intelligence and increasing complexity continues as long as two conditions are met: further increases in sensing and processing are sufficiently accessible to the evolutionary process, and the selection pressure is sufficient to drive it. Either condition can fail. Thus generally a plateau of dynamic equilibrium is reached. But it is also possible that under the right conditions, which we will return to below, the ratcheting of both complexity and intelligence may continue and accelerate.”
Grisogono then moves on to a fascinating and admirably succinct discussion of “what we have learned about the specific limitations that plague human decision-makers in complex problems. We can break this down into two parts: the aspects of complex problems that we find so difficult, and what it is about our brains that limits our ability to cope with those aspects.”
She begins by noting that, “Interdependence is a defining feature of complexity and has many challenging and interesting consequences. In particular, the network of interdependencies between different elements of the problem means that it cannot be successfully treated by dividing it into sub-problems that can be handled separately. Any attempt to do that creates more problems than it solves because of the interactions between the partial solutions…
“There is no natural boundary that completely isolates a complex problem from the context it is embedded in. There is always some traffic of information, resources, and agents in and out of the situation that can bring about unexpected changes, and therefore the context cannot be excluded from attention…
“Complex problems exist at multiple scales, with different agents, behaviors and properties at each, but with interactions between scales. This includes emergence, the appearance of complex structure and dynamics at larger scales as a result of smaller-scale phenomena, and its converse, top-down causation, whereby events or properties at a larger scale can alter what is happening at the smaller scales. In general, all the scales are important, and there is no single “right” scale at which to act…
“Interdependence implies multiple interacting causal and influence pathways leading to, and fanning out from, any event or property, so simple causality (one cause—one effect), or linear causal chains will not hold in general. Yet much of our cultural conditioning is predicated on a naïve view of linear causal chains, such as finding “the cause” of an effect, or “the person” to be held responsible for something, or “the cure” for a problem. Focusing on singular or primary causes makes it more difficult to intervene effectively in complex systems and produce desired outcomes without attendant undesired ones—so-called “side-effects” or unintended consequences…
“Furthermore, such networks of interactions between contributing factors can produce emergent behaviors which are not readily attributable or intuitively anticipatable or comprehensible, implying unknown risks and unrecognized opportunities” ...
“Many important aspects of complex problems are hidden, so there is inevitable uncertainty as to how the events and properties that are observable, are linked through causal and influence pathways, and therefore many hypotheses about them are possible. These cannot be easily distinguished based on the available evidence…
As if complexity isn’t enough, “there are generally multiple interdependent goals in a complex problem, both positive and negative, poorly framed, often unrealistic or conflicted, vague or not explicitly stated, and stakeholders will often disagree on the weights to place on the different goals, or change their minds. Achieving sufficient high level goal clarity to develop concrete goals for action is in itself a complex problem…
Grisogono then summarizes the cognitive abilities that are needed to successfully engage with complex problems.
“One immediate conclusion that can be drawn is that there is a massive requirement for cognitive bandwidth—not only to keep all the relevant aspects at all the relevant scales in mind as one seeks to understand the nature of the problem and what may be possible to do, but even more challenging, to incorporate appropriate non-linear dynamics as trajectories in time are explored…
“But there is a more fundamental problem that needs to be addressed first: how to acquire the necessary relevant information about the composition, structure and dynamics of the complex problem and its context at all the necessary scales, and revise and update it as it evolves. This requires a stance of continuous learning, i.e., simultaneous sensing, testing, learning and updating across all the dimensions and scales of the problem, and the ability to discover and access relevant sources of information. At their best, humans are okay at this, up to a point, but not at the sheer scale and tempo of what is required in real world complex problems which refuse to stand still while we catch up…
“To understand how all these factors interact to limit human competence in managing complex problems, and what opportunities might exist for mitigating them through advanced AI systems, we now review some key findings from relevant research.
“In particular we are interested in learning about the nature of human decision-making in the context of attempting to manage an ongoing situation which is sufficiently protracted and complex to defeat most, but not all, decision-makers.
“Drawing useful conclusions about the detailed decision-making behaviors that tend to either sow the seeds of later catastrophes, or build a basis for sustained success, calls for an extensive body of empirical data from many diverse human subjects making complex decisions in controllable and repeatable complex situations. Clearly this is a tall ask, so not surprisingly, the field is sparse.
"However, one such research program [led by Dietrich Dorner and his team], which has produced important insights about how successful and unsuccessful decision-making behaviors differ, stands out in having also addressed the underlying neurocognitive and affective processes that conspire to make it very difficult for human decision-makers to maintain the more successful behaviors, and to avoid falling into a vicious cycle of less effective behaviors.
“In brief, through years of experimentation with human subjects attempting to achieve complex goals in computer-based micro-worlds with complex underlying dynamics, the specific decision-making behaviors that differentiated a small minority of subjects who achieved acceptable outcomes in the longer term, from the majority who failed to do so, were identified. Results indicated that most subjects could score some quick wins early in the game, but as the unintended consequences of their actions developed and confronted them, and their attempts to deal with them created further problems, the performance of the overwhelming majority (90%) quickly deteriorated, pushing their micro-worlds into catastrophic or chronic failure.
“As would be expected, their detailed behaviors reproduced many well-documented findings about the cognitive traps posed by human heuristics and biases. Low ambiguity tolerance was found to be a significant factor in precipitating the behavior of prematurely jumping to conclusions about the problem and what was to be done about it, when faced with situational uncertainty, ambiguity and pressure to achieve high-level goals. The chosen (usually ineffective) course of action was then defended and persevered with through a combination of confirmation bias, commitment bias, and loss aversion, in spite of available contradictory evidence.
"The unfolding disaster was compounded by a number of other reasoning shortcomings such as difficulties in steering processes with long latencies and in projecting cumulative and non-linear processes. Overall they had poor situation understanding, were likely to focus on symptoms rather than causal factors, were prone to a number of dysfunctional behavior patterns, and attributed their failures to external causes rather than learning from them and taking responsibility for the outcomes they produced.
“By contrast, the remaining ten percent who eventually found ways to stabilize their micro-world, showed systematic differences in their decision-making behaviors and were able to counter the same innate tendencies by taking what amounts to an adaptive approach, developing a conceptual model of the situation, and a stratagem based on causal factors, seeking to learn from unexpected outcomes, and constantly challenging their own thinking and views. Most importantly, they displayed a higher degree of ambiguity tolerance than the unsuccessful majority.
These findings are particularly significant here because most of the individual human decision-making literature has concentrated on how complex decision-making fails, not on how it succeeds. However, insights from research into successful organizational decision-making in complex environments corroborate the importance of taking an adaptive approach.
“In summary, analysis of the effective decision behaviors offers important insights into what is needed, in both human capabilities and AI support, to deal with even higher levels of complexity beyond current human competence. There are two complementary aspects here—put simply: how to avoid pitfalls (what not to do), and how to adopt more successful approaches (what to do instead).
“It is not difficult to understand how the decision making behaviors associated with the majority contributed to their lack of success, nor how those of the rest enabled them to develop sufficient conceptual and practical understanding to manage and guide the situation to an acceptable regime. Indeed if the two lists of behaviors are presented to an audience, everyone can readily identify which list leads to successful outcomes and which leads to failure.
"Yet if those same individuals are placed in the micro-world hot seat, 90% of them will display the very behaviors they just identified as likely to be unsuccessful. This implies that the displayed behaviors are not the result of conscious rational choice, but are driven to some extent by unconscious processes...
“This observation informed development of a theoretical model [by Dorner and his team] incorporating both cognitive and neurophysiological processes to explain the observed data. In brief, the model postulates two basic psychological drives that are particularly relevant to complex decision making, a need for certainty and a need for competence. These are pictured metaphorically as tanks that can be topped up by signals of certainty (one’s expectations being met) and signals of competence (one’s actions producing desired outcomes), and drained by their opposites—surprises and unsuccessful actions.
“The difference between the current level and the set point of a tank creates a powerful unconscious need, stimulating some behavioral tendencies and suppressing others, and impacting on cognitive functions through stimulation of physiological stress. If both levels are sufficient the result is motivation to explore, reflect, seek information and take risky action if necessary—all necessary components of effective decision making behavior.
"But if the levels get too low the individual becomes anxious and is instead driven to flee, look for reassurance from others, seek only information that confirms his existing views so as to top up his dangerously low senses of certainty and competence, and deny or marginalize any tank draining contradictory information…
“The impacts of stress on cognitive functions reinforce these tendencies by reducing abilities to concentrate, sustain a course of action, and recall relevant knowledge. Individuals whose tanks are low therefore find it difficult to sustain the decision-making behaviors associated with success, and are likely to act in ways that generate further draining signals, digging themselves deeper into a vicious cycle of failure.
“We can now understand the 90:10 ratio, as the competing attractors are not symmetric—the vicious cycle of the less effective decision behaviors is self-reinforcing and robust, while the virtuous cycle of success is more fragile because one’s actions are not the sole determinant of outcomes in a complex situation, so even the best decision-makers will sometimes find their tanks getting depleted, and therefore have difficulty sustaining the more effective decision making behaviors.
“Further research has demonstrated that the more effective decision making behaviors are trainable to some extent, but because they entail changing meta-cognitive habits they require considerable practice, reinforcement and ongoing support.
"However, the scope for significant enhancement of unaided human complex decision making competence is limited—not only in the level of competence achievable, but also and more importantly, in the degree of complexity that can be managed. Meanwhile, the requirements for increased competence, and the inexorable rise in degree of complexity to be managed, continue to grow.”
In the remainder of the paper, Grisogono lays out the requirements for an AI system that could substantially improve our ability to make good decisions when confronted with complex, wicked problems. She concludes that current AI technology is far from what we need.
"Despite its successes, the best examples of AI are still very specialized applications that focus on well-defined domains, and that generally require a vast amount of training data to achieve their high performance. Such applications can certainly be components of an AI decision support system for managing very complex problems, but the factors [already] discussed imply that much more is needed: not just depth in narrow aspects, but breadth of scope by connecting the necessary components so as to create a virtual environment which is a sufficiently valid model of the problem and its context, and in which decision-makers can safely explore and test options for robustness and effectiveness, while being supported in maintaining effective decision making behaviors and resisting the less effective ones.”
Until AI-based decision support systems like this are developed, human beings’ batting average in successfully resolving the growing number of wicked problems we face is destined to remain low, and our few successes heavily dependent on a very small set of uniquely talented people who have a superior intuitive grasp of the nature and behavior of complex adaptive systems. In the short-term and medium-term, our critical challenge is how to increase their number.
How to Effectively Communicate Forecast Probability and Analytic Confidence
06/Feb/21 14:11
At Britten Coyne Partners, we have often observed that research on issues related to anticipating, assessing, and adapting in time to emergent strategic threats is poorly shared across the military, intelligence, academic, and practitioner communities. This post is another of our ongoing attempts to share key research findings across these silos.
David Mandel is a senior scientist at Defense Research and Development Canada, specializing in intelligence, influence, and collaboration issues. Based on our review of the research, we regard Mandel as a world leader in the effective communication of forecast probability and uncertainty, which is the subject of this post.
Background
Many analysts agree that, even before the COVID pandemic arrived, the world had entered a period of “unprecedented” or “radical” uncertainty and disruptive change.
In this environment, avoiding strategic failure in part depends on effectively meeting three forecasting challenges:
• Asking the right forecasting questions;
• Accurately estimating the probability of different outcomes; and
• Effectively communicating the degree and nature of the uncertainty associated with your forecast.
As we have noted in past posts on our Strategic Risk Blog, as well as in our Strategic Risk Governance and Management course, techniques to help forecasters ask the right questions have received moderate attention.
That said, some powerful methods have been developed, including scenario analysis (which I first encountered in 1984 when taking a course from Pierre Wack, who popularized it at Shell); prospective hindsight, such as Gary Klein’s pre-mortem method; and Robert Lempert and Steven Bankes’ exploratory ensemble modeling approach.
In contrast to the challenge of asking the right questions, much greater attention has been paid to the development of methods to help analysts accurately forecast the answers to them, particularly in the context of complex adaptive systems (which generate most of the uncertainty we confront today).
In addition to the extensive research on this challenge conducted by the intelligence and military communities, we have also recently seen many excellent academic and commercial works, including best selling books like “Future Babble” by Dan Gardner, “Superforecasting” by Philip Tetlock and Dan Gardner, and “The Signal and the Noise” by Nate Sliver.
Compared to the first two challenges, the critical issue of forecast uncertainty, and in particular how to effectively communicate it, has received far less attention.
Some authors have constructed taxonomies to describe the sources of forecast uncertainty (e.g., “Classifying and Communicating Uncertainties in Model-Based Policy Analysis," by Kwakkel, Walker, and Marchau).
Other analysts have attempted to estimate the likely extent of forecast uncertainty in complex adaptive systems.
For example, in “The Prevalence Of Chaotic Dynamics In Games With Many Players”, Sanders et al find that in games where players can take many possible actions in every period in pursuit of their long-term goals (which may differ), system behavior quickly becomes chaotic and unpredictable as the number of players increases. The authors conclude that, “complex non-equilibrium behavior, exemplified by chaos, may be the norm for complicated games with many players.”
In “Prediction and Explanation in Social Systems”, Hoffman et al also analyze the limits to predictability in complex adaptive social systems.
They observe, “How predictable is human behavior? There is no single answer to this question because human behavior spans the gamut from highly regular to wildly unpredictable. At one extreme, a study of 50,000 mobile phone users found that in any given hour, users were in their most visited location 70% of the time; thus, on average, one could achieve 70% prediction accuracy with the simple heuristic, ‘Jane will be at her usual spot today’.”
“At the other extreme, so-called ‘black swan’ events are thought to be intrinsically impossible to predict in any meaningful sense. Last, for outcomes of intermediate predictability, such as presidential elections, stock market movements, and feature films’ revenues, the difficulty of prediction can vary tremendously with the details of the task.”
The authors note that, “the more that outcomes are determined by extrinsic random factors, the lower the theoretical best performance that can be attained by any method.”
In “Exploring Limits to Prediction in Complex Social Systems”, Martin et al also address the question, “How predictable is success in complex social systems?” To analyze it, they evaluate the ability of multiple methodologies to predict the size and duration of Twitter cascades.
The authors conclude that, “Despite an unprecedented volume of information about users, content, and past performance, our best performing models can explain less than half of the variance in cascade sizes … This result suggests that even with unlimited data predictive performance would be bounded well below deterministic accuracy.”
“Although higher predictive power [than what we achieved] is possible in theory, such performance requires a homogeneous system and perfect ex-ante knowledge of it: even a small degree of uncertainty … leads to substantially more restrictive bounds on predictability … We conclude that such bounds [on predictability] for other complex social systems for which data are more difficult to obtain are likely even lower.”
In sum, forecasts of future outcomes produced by complex adaptive systems (e.g., the economy, financial markets, product markets, interacting combatants, etc.) are very likely to be accompanied by a substantial amount of uncertainty.
David Mandel’s Insights
A critical question is how to effectively communicate a forecast’s probability and its associated uncertainty to decision makers.
A recent review concluded that, given its importance, this is an issue that surprisingly has not received much attention from researchers (“Communicating Uncertainty About Facts, Numbers And Science”, by van der Bles et al).
That is somewhat strange, because this is not a new problem.
For example, in 1964 the CIA’s Sherman Kent published his confidential memo on “Words of Estimative Probability”, which highlighted the widely varying numerical probabilities that different people attached to verbal expressions such as “possible”, “likely”, “probable”, or “almost certain”. Over the succeeding fifty years, multiple studies have replicated and extended Kent’s conclusions.
Yet in practice, verbal expressions of estimative probability, without accompanying quantitative expressions, still widely used.
For example, it was only after recommendations from the 9/11 Commission Report, and direction by the Intelligence Reform and Terrorism Prevention Act (IRTPA) of 2004, that on 21 June 2007 the Office of the Director of National Intelligence (DNI) released Intelligence Community (IC) Directive (ICD) 203.
This Directive established intelligence community-wide analytic standards intended to, “meet the highest standards of integrity and rigorous analytic thinking.”
ICD 203 includes the following table for translating “words of estimative probability” into quantitative probability estimates:
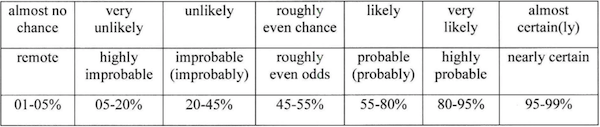
In our experience, nobody has written more about these issues than David Mandel.
To be sure, “Assessing Uncertainty in Intelligence” by Friedman and Zeckhauser is an important paper. However, it pales in comparison to the volume and breadth of Mandel’s research, including his contributions to and editorship of NATO’s exhaustive June 2020 report on “Assessment and Communication of Uncertainty in Intelligence to Support Decision-Making”.
In what follows, we’ll review some of his Mandel’s key findings, insights, and recommendations in three critical areas: (1) Communicating probability forecasts; (2) Communicating the degree of forecast uncertainty (or “analytic confidence”); and (3) Why organizations have been reluctant to adopt what researchers have found to be the most effective practices in both these areas.
Effectively Communicating Probability Forecasts
“As Sherman Kent aptly noted [in 1964], substantive intelligence is largely human judgment made under conditions of uncertainty. Among the most important assessments are those that not only concern unknowns but also potentially unknowables, such as the partially formed intentions of a leader in an adversarial state.”
“In such cases, the primary task of the analyst is not to state what will happen but to accurately assess the probabilities of alternative possibilities as well as the degree of error in the assessments and to giver clear explanations for the basis of such assessments.” (Source: “Intelligence, Science, and the Ignorance Hypothesis”, by David Mandel).
“Most intelligence organizations today use some variant of the Kent-Foster approach. That is, they rely on curated sets of linguistic probability terms presented as ordered scales. Previously, some of these scales did not use numeric probability equivalencies. However, nowadays most standards assign numeric ranges to stipulate the meaning of each linguistic probability term.”
“Efforts to transform the vagueness of natural language into something clearer reflect a noble goal, but the curated-list approach is flawed in practice and in principle. For example, flaws in practice include the fact that each standard uses a common approach, yet each differs sufficiently to undermine interoperability among key collaborative partners; e.g., an even chance issued by NATO could mean unlikely, roughly even chance, or likely in the US system.”
“Current standards also prevent analysts from communicating probabilities less than 1% or greater than 99%. This pre-empts analysts from distinguishing “one in a hundred” from “one in a million.” In the US standard, “one in a hundred” is the smallest communicable probability, while in the NATO and UK standards, “one in a million” would be indistinguishable from “one in ten.” Orders of magnitude should matter to experts because orders of magnitude matter in everyday life. A threat that has a 10% chance of occurring may call for a different response than if it had a one-in-a-million chance of occurring instead.”
“Intelligence organizations have naively assumed that they can quash the unruliness of linguistic probabilities simply by stating their intended meaning. Yet ample research shows that when people have direct access to a translation table, a large proportion still interprets linguistic expressions inconsistently with the prescribed meanings.”
“Noting the abysmal rates of shared understanding when probability lexicons are provided, researchers have recommended that numeric ranges be reported alongside linguistic probabilities in assessments [as in ICD 203]. However, this approach has yielded only modest improvements in shared understanding.”
“Studies show that people generally prefer to communicate probabilistic information linguistically, but that they also prefer to receive it numerically. These preferences are exhibited across a range of expert judgment communities, but are particularly pronounced when judgments are based on unreliable or incomplete information, as is characteristic of intelligence analysis.”
“Decision-makers want useful (i.e., timely, relevant, and accurate) information to support their decisions; they don’t wish to be reminded repeatedly what probability terms should mean to them when consuming intelligence. Any standard that encourages analysts to express anything other than their best probability estimate for the event being judged is suboptimal.”
Mandel also stresses that, “Explanation is [also] vital to intelligence since without it, a decision-maker would not know how the particular assessment was reached. Numeric assessments and clear explanations should work together to yield effective intelligence.”
(Source: “Uncertainty, Intelligence, and National Security Decision Making”, by David Mandel and Daniel Irwin).
Related research has also found that allowing forecasters to use narrower probability ranges than those specified in national guidelines like ICD-203. (See “The Value of Precision in Probability Assessment: Evidence from a Large-Scale Geopolitical Forecasting Tournament”, by Friedman et al).
Another problem is that, “Linguistic probabilities also convey ‘directionality,’ a linguistic feature related to but distinct from probability.
“Directionality is a characteristic of probabilistic statements that calls attention to the potential occurrence or non-occurrence of an event. For instance, if someone tells you there is some chance they will make it to an event, you will probably be more inclined to expect them to attend than if they had said it was doubtful, even though both terms tend to be understood as conveying low probabilities … These implicit suggestions can influence decision-making outside of the decision-maker’s awareness.” (Source: “Uncertainty, Intelligence, and National Security Decision Making”, by David Mandel and Daniel Irwin).
“Communicating probabilities numerically rather than verbally also benefits forecasters’ credibility. Verbal probabilities convey implicit recommendations more clearly than probability information, whereas numeric probabilities do the opposite. Prescriptively, we propose that experts distinguish forecasts from advice, using numeric probabilities for the former and well-reasoned arguments for the latter.” (Source: “Cultivating Credibility With Probability Words And Numbers”, by Robert Collins and David Mandel).
Effectively Communicating Forecast Confidence (or Uncertainty)
Probabilistic forecasts are based rest on a combinations of (1) facts, (2) assumptions about critical uncertainties; (3) the evidence (of varying reliability and information value) supporting those assumptions; and (4) the logic used to reach the forecaster’s conclusion.
A forecast is typically assessed either directly (by judging the strength of its assumptions and logic), or indirectly, on the basis of the forecaster’s stated confidence in her/his conclusions.
In our forecasting work with clients over the years, we have found that discussing the assumptions made about critical uncertainties, and, less frequently the forecast logic itself, generates very productive discussions and improved predictive accuracy.
In particular, we have found Marvin Cohen’s approach quite practical. His research found that the greater the number of assumptions about “known unknowns” [i.e., recognized uncertainties] that underlie a forecast, and the weaker the evidence that supports them, the lower confidence one should have in the forecast’s accuracy.
Cohen also cautions that the more assumptions about “known unknowns” that are used in a forecast logic, the more likely it is that more potentially critical “unknown unknowns” remain to be discovered, which again should lower your confidence in the forecast (e.g., see, “Metarecognition in Time-Stressed Decision Making: Recognizing, Critiquing, and Correcting”, by Cohen, Freeman, and Wolf).
Mandel focuses on expressions of “analytic confidence” in a forecast, which are the established practice in the intelligence world.
In a number of different publications, he highlights many shortcomings in the ways that analytic confidence is currently communicated to users of estimative probability forecasts.
“Given that intelligence is typically derived from incomplete and ambiguous evidence, analysts must accurately assess and communicate their level of uncertainty to consumers. One facet of this perennial challenge is the communication of analytic confidence, or the level of confidence that an analyst has in his or her judgments, including those already qualified by probability terms such as “very unlikely” or “almost certainly”.
“Analytic confidence levels indicate the extent to which “assessments and estimates are supported by information that varies in scope, quality and sourcing.”
“Consumers [i.e., forecast users] are better equipped to make sound decisions when they understand the methodological and evidential strength (or flimsiness) of intelligence assessments. Effective communication of confidence also militates against the pernicious misconception that the Intelligence Community (IC) is omniscient.”
“Most intelligence organizations have adopted standardized lexicons for rating and communicating analytic confidence. These standards provide a range of confidence levels (e.g., high, moderate, low), along with relevant rating criteria…
“There is evidence that expressions of confidence are easily misinterpreted by consumers … There is also evidence that the terms stipulated in confidence standards are misunderstood (or at least misapplied) by intelligence practitioners.”
“For example, here is the three level confidence scale used by the Canadian Forces Intelligence Command (CFINTCOM):

In the CFINTCOM framework, “Analytic confidence is based on three main factors:
(1) Evidence: “the strength of the knowledge base, to include the quality of the evidence and our depth of understanding about the issue.”
(2) Assumptions: “the number and importance of assumptions used to fill information gaps.”
(3) Reasoning: “the strength of the logic underpinning the argument, which encompasses the number and strength of analytic inferences as well as the rigour of the analytic methodology applied to the product.”
To show how widely standards for communicating forecast confidence vary, Mandel contrasts those used by intelligence and military organizations with the framework and ratings used by the Intergovernmental Panel on Climate Change (IPCC):

After comparing the approaches used by different NATO members, Mandel finds that, “The analytic confidence standards examined generally incorporate the following determinants:
• Source reliability;
• Information credibility;
• Evidence consistency/convergence;
• Strength of logic/reasoning; and
• Quantity and significance of assumptions and information gaps.”
However, he also notes that, “few [national] standards attempt to operationalize these determinants or outline formal mechanisms for evaluation. Instead, they tend to provide vague, qualitative descriptions for each confidence level, which may lead to inconsistent confidence assessments.”
“Issues may also arise from the emphasis most standards place on evidence convergence as a determinant of analytic confidence … Convergence can help eliminate false assumptions and false/deceptive information, but may not necessarily prevent analysts from deriving high confidence from outdated information. Under current standards, a large body of highly credible and consistent information could contribute to high analytic confidence, despite being out of date. A possible solution would be to incorporate a measure of information recency”.
“The emphasis on convergence may also lead analysts to inflate their confidence by accumulating seemingly useful but redundant information” (e.g., multiple reports based on same underlying data).
“In evaluating information convergence, confidence standards also fail to weigh the reliability of confirming sources against disconfirming sources, or how relationships between sources may unduly influence their likelihood of convergence. Focusing heavily on convergence can also introduce order effects, whereby information received earlier faces fewer hurdles to being judged credible.”
Mandel concludes, “It is unlikely that current analytic confidence standards incorporate all relevant determinants. For instance, confidence levels, as traditionally expressed, fail to consider how much estimates might shift with additional information, which is often a key consideration for consumers deciding how to act on an estimate.
“Under certain circumstances, the information content of an assessment may be less relevant to decision makers than how much that information (and the resultant forecast estimate) may change in the future. Analytic confidence scales could incorporate a measure of “responsiveness,” expressed as the probability that an estimate will change due to additional collection and analysis over a given time period (e.g., there is a 70% chance of x, but by the end of the month, there is a 50% chance that additional intelligence will increase the estimated likelihood of x to 90%).”
“In addition to responsiveness and evidence characteristics, current conceptions of analytic confidence fail to convey the level of consensus or range of reasonable opinion about a given estimate. Analysts can arguably assess uncertainty more effectively when the range of plausible viewpoints is narrower, and evidence characteristics and the range of reasonable opinion vary independently.”
For example, “In climate science, different assumptions between scientific models can lead researchers to predict significantly different outcomes using the same data. For this reason, current climate science standards incorporate model agreement/consensus as a determinant of analytic confidence.”
(Source: “How Intelligence Organizations Communicate Confidence (Unclearly)”, by Daniel Irwin and David Mandel).
Mandel also observes that, “analysts are usually instructed to assess probability and confidence as if they were independent constructs. This fails to explain that confidence is a second-order judgment of uncertainty capturing one’s subjective margin of error in a probabilistic estimate. That is, the less confident analysts are in their estimates, the wider their credible probability intervals should be.
“An analyst who believes the probability of an event lies between 50% and 90% (i.e., 70% plus or minus 20%) is less confident than an analyst who believes that the probability lies between 65% and 75% (i.e., 70% plus or minus 5%). The analyst providing the wider margin of error plays it safer than the analyst providing the narrower interval, presumably because the former is less confident than the latter.”
(Source: “Uncertainty, Intelligence, and National Security Decision Making”, by David Mandel and Daniel Irwin).
Organizational Obstacles to Adopting More Effective Methods
In words that are equally applicable to the private sector forecasts, Mandel notes that, “intelligence analysis and national security decision-making are pervaded by uncertainty. The centrality of uncertainty to decision-making at the highest policy levels underscores the primacy of accurately assessing and clearly communicating uncertainties to decision-makers. This is a central analytic function of intelligence.”
“Most substantive intelligence is not fact but expert judgment made under uncertainty. Not only does the analyst have to reason through uncertainties to arrive at sound and hopefully accurate judgments, but the uncertainties must also be clearly communicated to policymakers who must decide how to act upon the intelligence.”
“Thomas Fingar, former US Deputy Director of National Intelligence, described the role of intelligence as centrally focusing on reducing uncertainty for the decision-maker. While analysts cannot always reduce uncertainty, they should be able to accurately estimate and clearly communicate key uncertainties for decision-makers.”
“Given the importance of uncertainty in intelligence, one might expect the intelligence community to draw upon relevant science aimed at effectively handling uncertainty, much as it has done to fuel its vast collections capabilities. Yet remarkably, methods for uncertainty communication are far from having been optimized, even though the problem of uncertainty communication has resurfaced in connection with significant intelligence failures.”
We could make the same argument about the importance of accurately assessing uncertainty and emerging strategic threats in the private sector, and its association with many corporate failures. As directors, executives, and consultant, we have frequently observed the absence of best practices for communicating forecast uncertainty in private sector organizations around the world.
Mandel goes on, “Given the shortcomings of the current approach to uncertainty communication and the clear benefits of using numeric probabilities, why hasn’t effective reform happened?”
“In part, organizational inertia reflects the fact that most intelligence consumers have limited time in office, finite political capital, and crowded agendas. Efforts to tackle intelligence-community esoterica deplete resources and promise little in the way of electoral payoff. High turnover of elected officials also ensures short collective memory; practitioners can count on mistakes being forgotten without having to modify their tradecraft [i.e., analytical practices]. Even when commissions are expressly tasked with intelligence reform, they often lack the requisite knowledge base, resulting in superficial solutions.”
“Beyond these institutional barriers, intelligence producers and consumers alike may view it in their best interests to sacrifice epistemic quality in intelligence to better serve other pragmatic goals.”
“For forecast consumers, linguistic probabilities provide wiggle room to interpret intelligence estimates in ways that align with their policy preconceptions and preferences—and if things go wrong, they have the intelligence community to blame for its lack of clarity. Historically, intelligence consumers have exploited imprecision to justify decisions and deflect blame when they produced negative outcomes.”
Unfortunately, that’s equally true in the private sector.
(Source: “Uncertainty, Intelligence, and National Security Decision Making”, by David Mandel and Daniel Irwin).
However, it’s not just forecast consumers who are to blame for the current state of affairs. As Mandel notes, “Given that there is far more to lose by overconfidently asserting claims that prove to be false than by underconfidently making claims that prove to be true, intelligence organizations are likely motivated to make timid forecasts that water down information value to decision-makers—a play-it-safe strategy that anticipates unwelcome entry into the political blame games that punctuate history.”
(Source: “Intelligence, Science and the Ignorance Hypothesis”, by David Mandel)
Conclusion
As we noted at the outset, even before the COVID pandemic arrived the world had entered a period of unprecedented or radical uncertainty and disruptive change.
In this environment, avoiding failure in part depends on effectively meeting three forecasting challenges:
• Asking the right forecasting questions;
• Accurately estimating their possible outcomes; and
• Effectively communicating the degree and nature of the uncertainty associated with your forecast.
Meeting these challenges has proven to be difficult in the world of professional intelligence analysis; this is even more so the case in the private sector, as the history of corporate failure painfully shows.
Of these three challenges, effectively communicating the degree and nature of the uncertainty associated with forecasts has received the least attention.
Fortunately, David Mandel has made it his focus. His research is too little known and appreciated outside the intelligence community (and even within it, unfortunately).
By briefly summarizing his research here, we hope Mandel’s work can help far more organizations to improve their forecasting practices and substantially improve their chances of avoiding failure and achieving their goals.
Britten Coyne Partners advises clients how to establish methods, processes, structures, and systems that enable them to better anticipate, accurately assess, and adapt in time to emerging threats and avoid strategic failures. Through our affiliate, The Strategic Risk Institute, we also provide online and in-person courses leading to a Certificate in Strategic Risk Governance and Management.
David Mandel is a senior scientist at Defense Research and Development Canada, specializing in intelligence, influence, and collaboration issues. Based on our review of the research, we regard Mandel as a world leader in the effective communication of forecast probability and uncertainty, which is the subject of this post.
Background
Many analysts agree that, even before the COVID pandemic arrived, the world had entered a period of “unprecedented” or “radical” uncertainty and disruptive change.
In this environment, avoiding strategic failure in part depends on effectively meeting three forecasting challenges:
• Asking the right forecasting questions;
• Accurately estimating the probability of different outcomes; and
• Effectively communicating the degree and nature of the uncertainty associated with your forecast.
As we have noted in past posts on our Strategic Risk Blog, as well as in our Strategic Risk Governance and Management course, techniques to help forecasters ask the right questions have received moderate attention.
That said, some powerful methods have been developed, including scenario analysis (which I first encountered in 1984 when taking a course from Pierre Wack, who popularized it at Shell); prospective hindsight, such as Gary Klein’s pre-mortem method; and Robert Lempert and Steven Bankes’ exploratory ensemble modeling approach.
In contrast to the challenge of asking the right questions, much greater attention has been paid to the development of methods to help analysts accurately forecast the answers to them, particularly in the context of complex adaptive systems (which generate most of the uncertainty we confront today).
In addition to the extensive research on this challenge conducted by the intelligence and military communities, we have also recently seen many excellent academic and commercial works, including best selling books like “Future Babble” by Dan Gardner, “Superforecasting” by Philip Tetlock and Dan Gardner, and “The Signal and the Noise” by Nate Sliver.
Compared to the first two challenges, the critical issue of forecast uncertainty, and in particular how to effectively communicate it, has received far less attention.
Some authors have constructed taxonomies to describe the sources of forecast uncertainty (e.g., “Classifying and Communicating Uncertainties in Model-Based Policy Analysis," by Kwakkel, Walker, and Marchau).
Other analysts have attempted to estimate the likely extent of forecast uncertainty in complex adaptive systems.
For example, in “The Prevalence Of Chaotic Dynamics In Games With Many Players”, Sanders et al find that in games where players can take many possible actions in every period in pursuit of their long-term goals (which may differ), system behavior quickly becomes chaotic and unpredictable as the number of players increases. The authors conclude that, “complex non-equilibrium behavior, exemplified by chaos, may be the norm for complicated games with many players.”
In “Prediction and Explanation in Social Systems”, Hoffman et al also analyze the limits to predictability in complex adaptive social systems.
They observe, “How predictable is human behavior? There is no single answer to this question because human behavior spans the gamut from highly regular to wildly unpredictable. At one extreme, a study of 50,000 mobile phone users found that in any given hour, users were in their most visited location 70% of the time; thus, on average, one could achieve 70% prediction accuracy with the simple heuristic, ‘Jane will be at her usual spot today’.”
“At the other extreme, so-called ‘black swan’ events are thought to be intrinsically impossible to predict in any meaningful sense. Last, for outcomes of intermediate predictability, such as presidential elections, stock market movements, and feature films’ revenues, the difficulty of prediction can vary tremendously with the details of the task.”
The authors note that, “the more that outcomes are determined by extrinsic random factors, the lower the theoretical best performance that can be attained by any method.”
In “Exploring Limits to Prediction in Complex Social Systems”, Martin et al also address the question, “How predictable is success in complex social systems?” To analyze it, they evaluate the ability of multiple methodologies to predict the size and duration of Twitter cascades.
The authors conclude that, “Despite an unprecedented volume of information about users, content, and past performance, our best performing models can explain less than half of the variance in cascade sizes … This result suggests that even with unlimited data predictive performance would be bounded well below deterministic accuracy.”
“Although higher predictive power [than what we achieved] is possible in theory, such performance requires a homogeneous system and perfect ex-ante knowledge of it: even a small degree of uncertainty … leads to substantially more restrictive bounds on predictability … We conclude that such bounds [on predictability] for other complex social systems for which data are more difficult to obtain are likely even lower.”
In sum, forecasts of future outcomes produced by complex adaptive systems (e.g., the economy, financial markets, product markets, interacting combatants, etc.) are very likely to be accompanied by a substantial amount of uncertainty.
David Mandel’s Insights
A critical question is how to effectively communicate a forecast’s probability and its associated uncertainty to decision makers.
A recent review concluded that, given its importance, this is an issue that surprisingly has not received much attention from researchers (“Communicating Uncertainty About Facts, Numbers And Science”, by van der Bles et al).
That is somewhat strange, because this is not a new problem.
For example, in 1964 the CIA’s Sherman Kent published his confidential memo on “Words of Estimative Probability”, which highlighted the widely varying numerical probabilities that different people attached to verbal expressions such as “possible”, “likely”, “probable”, or “almost certain”. Over the succeeding fifty years, multiple studies have replicated and extended Kent’s conclusions.
Yet in practice, verbal expressions of estimative probability, without accompanying quantitative expressions, still widely used.
For example, it was only after recommendations from the 9/11 Commission Report, and direction by the Intelligence Reform and Terrorism Prevention Act (IRTPA) of 2004, that on 21 June 2007 the Office of the Director of National Intelligence (DNI) released Intelligence Community (IC) Directive (ICD) 203.
This Directive established intelligence community-wide analytic standards intended to, “meet the highest standards of integrity and rigorous analytic thinking.”
ICD 203 includes the following table for translating “words of estimative probability” into quantitative probability estimates:
In our experience, nobody has written more about these issues than David Mandel.
To be sure, “Assessing Uncertainty in Intelligence” by Friedman and Zeckhauser is an important paper. However, it pales in comparison to the volume and breadth of Mandel’s research, including his contributions to and editorship of NATO’s exhaustive June 2020 report on “Assessment and Communication of Uncertainty in Intelligence to Support Decision-Making”.
In what follows, we’ll review some of his Mandel’s key findings, insights, and recommendations in three critical areas: (1) Communicating probability forecasts; (2) Communicating the degree of forecast uncertainty (or “analytic confidence”); and (3) Why organizations have been reluctant to adopt what researchers have found to be the most effective practices in both these areas.
Effectively Communicating Probability Forecasts
“As Sherman Kent aptly noted [in 1964], substantive intelligence is largely human judgment made under conditions of uncertainty. Among the most important assessments are those that not only concern unknowns but also potentially unknowables, such as the partially formed intentions of a leader in an adversarial state.”
“In such cases, the primary task of the analyst is not to state what will happen but to accurately assess the probabilities of alternative possibilities as well as the degree of error in the assessments and to giver clear explanations for the basis of such assessments.” (Source: “Intelligence, Science, and the Ignorance Hypothesis”, by David Mandel).
“Most intelligence organizations today use some variant of the Kent-Foster approach. That is, they rely on curated sets of linguistic probability terms presented as ordered scales. Previously, some of these scales did not use numeric probability equivalencies. However, nowadays most standards assign numeric ranges to stipulate the meaning of each linguistic probability term.”
“Efforts to transform the vagueness of natural language into something clearer reflect a noble goal, but the curated-list approach is flawed in practice and in principle. For example, flaws in practice include the fact that each standard uses a common approach, yet each differs sufficiently to undermine interoperability among key collaborative partners; e.g., an even chance issued by NATO could mean unlikely, roughly even chance, or likely in the US system.”
“Current standards also prevent analysts from communicating probabilities less than 1% or greater than 99%. This pre-empts analysts from distinguishing “one in a hundred” from “one in a million.” In the US standard, “one in a hundred” is the smallest communicable probability, while in the NATO and UK standards, “one in a million” would be indistinguishable from “one in ten.” Orders of magnitude should matter to experts because orders of magnitude matter in everyday life. A threat that has a 10% chance of occurring may call for a different response than if it had a one-in-a-million chance of occurring instead.”
“Intelligence organizations have naively assumed that they can quash the unruliness of linguistic probabilities simply by stating their intended meaning. Yet ample research shows that when people have direct access to a translation table, a large proportion still interprets linguistic expressions inconsistently with the prescribed meanings.”
“Noting the abysmal rates of shared understanding when probability lexicons are provided, researchers have recommended that numeric ranges be reported alongside linguistic probabilities in assessments [as in ICD 203]. However, this approach has yielded only modest improvements in shared understanding.”
“Studies show that people generally prefer to communicate probabilistic information linguistically, but that they also prefer to receive it numerically. These preferences are exhibited across a range of expert judgment communities, but are particularly pronounced when judgments are based on unreliable or incomplete information, as is characteristic of intelligence analysis.”
“Decision-makers want useful (i.e., timely, relevant, and accurate) information to support their decisions; they don’t wish to be reminded repeatedly what probability terms should mean to them when consuming intelligence. Any standard that encourages analysts to express anything other than their best probability estimate for the event being judged is suboptimal.”
Mandel also stresses that, “Explanation is [also] vital to intelligence since without it, a decision-maker would not know how the particular assessment was reached. Numeric assessments and clear explanations should work together to yield effective intelligence.”
(Source: “Uncertainty, Intelligence, and National Security Decision Making”, by David Mandel and Daniel Irwin).
Related research has also found that allowing forecasters to use narrower probability ranges than those specified in national guidelines like ICD-203. (See “The Value of Precision in Probability Assessment: Evidence from a Large-Scale Geopolitical Forecasting Tournament”, by Friedman et al).
Another problem is that, “Linguistic probabilities also convey ‘directionality,’ a linguistic feature related to but distinct from probability.
“Directionality is a characteristic of probabilistic statements that calls attention to the potential occurrence or non-occurrence of an event. For instance, if someone tells you there is some chance they will make it to an event, you will probably be more inclined to expect them to attend than if they had said it was doubtful, even though both terms tend to be understood as conveying low probabilities … These implicit suggestions can influence decision-making outside of the decision-maker’s awareness.” (Source: “Uncertainty, Intelligence, and National Security Decision Making”, by David Mandel and Daniel Irwin).
“Communicating probabilities numerically rather than verbally also benefits forecasters’ credibility. Verbal probabilities convey implicit recommendations more clearly than probability information, whereas numeric probabilities do the opposite. Prescriptively, we propose that experts distinguish forecasts from advice, using numeric probabilities for the former and well-reasoned arguments for the latter.” (Source: “Cultivating Credibility With Probability Words And Numbers”, by Robert Collins and David Mandel).
Effectively Communicating Forecast Confidence (or Uncertainty)
Probabilistic forecasts are based rest on a combinations of (1) facts, (2) assumptions about critical uncertainties; (3) the evidence (of varying reliability and information value) supporting those assumptions; and (4) the logic used to reach the forecaster’s conclusion.
A forecast is typically assessed either directly (by judging the strength of its assumptions and logic), or indirectly, on the basis of the forecaster’s stated confidence in her/his conclusions.
In our forecasting work with clients over the years, we have found that discussing the assumptions made about critical uncertainties, and, less frequently the forecast logic itself, generates very productive discussions and improved predictive accuracy.
In particular, we have found Marvin Cohen’s approach quite practical. His research found that the greater the number of assumptions about “known unknowns” [i.e., recognized uncertainties] that underlie a forecast, and the weaker the evidence that supports them, the lower confidence one should have in the forecast’s accuracy.
Cohen also cautions that the more assumptions about “known unknowns” that are used in a forecast logic, the more likely it is that more potentially critical “unknown unknowns” remain to be discovered, which again should lower your confidence in the forecast (e.g., see, “Metarecognition in Time-Stressed Decision Making: Recognizing, Critiquing, and Correcting”, by Cohen, Freeman, and Wolf).
Mandel focuses on expressions of “analytic confidence” in a forecast, which are the established practice in the intelligence world.
In a number of different publications, he highlights many shortcomings in the ways that analytic confidence is currently communicated to users of estimative probability forecasts.
“Given that intelligence is typically derived from incomplete and ambiguous evidence, analysts must accurately assess and communicate their level of uncertainty to consumers. One facet of this perennial challenge is the communication of analytic confidence, or the level of confidence that an analyst has in his or her judgments, including those already qualified by probability terms such as “very unlikely” or “almost certainly”.
“Analytic confidence levels indicate the extent to which “assessments and estimates are supported by information that varies in scope, quality and sourcing.”
“Consumers [i.e., forecast users] are better equipped to make sound decisions when they understand the methodological and evidential strength (or flimsiness) of intelligence assessments. Effective communication of confidence also militates against the pernicious misconception that the Intelligence Community (IC) is omniscient.”
“Most intelligence organizations have adopted standardized lexicons for rating and communicating analytic confidence. These standards provide a range of confidence levels (e.g., high, moderate, low), along with relevant rating criteria…
“There is evidence that expressions of confidence are easily misinterpreted by consumers … There is also evidence that the terms stipulated in confidence standards are misunderstood (or at least misapplied) by intelligence practitioners.”
“For example, here is the three level confidence scale used by the Canadian Forces Intelligence Command (CFINTCOM):
In the CFINTCOM framework, “Analytic confidence is based on three main factors:
(1) Evidence: “the strength of the knowledge base, to include the quality of the evidence and our depth of understanding about the issue.”
(2) Assumptions: “the number and importance of assumptions used to fill information gaps.”
(3) Reasoning: “the strength of the logic underpinning the argument, which encompasses the number and strength of analytic inferences as well as the rigour of the analytic methodology applied to the product.”
To show how widely standards for communicating forecast confidence vary, Mandel contrasts those used by intelligence and military organizations with the framework and ratings used by the Intergovernmental Panel on Climate Change (IPCC):
After comparing the approaches used by different NATO members, Mandel finds that, “The analytic confidence standards examined generally incorporate the following determinants:
• Source reliability;
• Information credibility;
• Evidence consistency/convergence;
• Strength of logic/reasoning; and
• Quantity and significance of assumptions and information gaps.”
However, he also notes that, “few [national] standards attempt to operationalize these determinants or outline formal mechanisms for evaluation. Instead, they tend to provide vague, qualitative descriptions for each confidence level, which may lead to inconsistent confidence assessments.”
“Issues may also arise from the emphasis most standards place on evidence convergence as a determinant of analytic confidence … Convergence can help eliminate false assumptions and false/deceptive information, but may not necessarily prevent analysts from deriving high confidence from outdated information. Under current standards, a large body of highly credible and consistent information could contribute to high analytic confidence, despite being out of date. A possible solution would be to incorporate a measure of information recency”.
“The emphasis on convergence may also lead analysts to inflate their confidence by accumulating seemingly useful but redundant information” (e.g., multiple reports based on same underlying data).
“In evaluating information convergence, confidence standards also fail to weigh the reliability of confirming sources against disconfirming sources, or how relationships between sources may unduly influence their likelihood of convergence. Focusing heavily on convergence can also introduce order effects, whereby information received earlier faces fewer hurdles to being judged credible.”
Mandel concludes, “It is unlikely that current analytic confidence standards incorporate all relevant determinants. For instance, confidence levels, as traditionally expressed, fail to consider how much estimates might shift with additional information, which is often a key consideration for consumers deciding how to act on an estimate.
“Under certain circumstances, the information content of an assessment may be less relevant to decision makers than how much that information (and the resultant forecast estimate) may change in the future. Analytic confidence scales could incorporate a measure of “responsiveness,” expressed as the probability that an estimate will change due to additional collection and analysis over a given time period (e.g., there is a 70% chance of x, but by the end of the month, there is a 50% chance that additional intelligence will increase the estimated likelihood of x to 90%).”
“In addition to responsiveness and evidence characteristics, current conceptions of analytic confidence fail to convey the level of consensus or range of reasonable opinion about a given estimate. Analysts can arguably assess uncertainty more effectively when the range of plausible viewpoints is narrower, and evidence characteristics and the range of reasonable opinion vary independently.”
For example, “In climate science, different assumptions between scientific models can lead researchers to predict significantly different outcomes using the same data. For this reason, current climate science standards incorporate model agreement/consensus as a determinant of analytic confidence.”
(Source: “How Intelligence Organizations Communicate Confidence (Unclearly)”, by Daniel Irwin and David Mandel).
Mandel also observes that, “analysts are usually instructed to assess probability and confidence as if they were independent constructs. This fails to explain that confidence is a second-order judgment of uncertainty capturing one’s subjective margin of error in a probabilistic estimate. That is, the less confident analysts are in their estimates, the wider their credible probability intervals should be.
“An analyst who believes the probability of an event lies between 50% and 90% (i.e., 70% plus or minus 20%) is less confident than an analyst who believes that the probability lies between 65% and 75% (i.e., 70% plus or minus 5%). The analyst providing the wider margin of error plays it safer than the analyst providing the narrower interval, presumably because the former is less confident than the latter.”
(Source: “Uncertainty, Intelligence, and National Security Decision Making”, by David Mandel and Daniel Irwin).
Organizational Obstacles to Adopting More Effective Methods
In words that are equally applicable to the private sector forecasts, Mandel notes that, “intelligence analysis and national security decision-making are pervaded by uncertainty. The centrality of uncertainty to decision-making at the highest policy levels underscores the primacy of accurately assessing and clearly communicating uncertainties to decision-makers. This is a central analytic function of intelligence.”
“Most substantive intelligence is not fact but expert judgment made under uncertainty. Not only does the analyst have to reason through uncertainties to arrive at sound and hopefully accurate judgments, but the uncertainties must also be clearly communicated to policymakers who must decide how to act upon the intelligence.”
“Thomas Fingar, former US Deputy Director of National Intelligence, described the role of intelligence as centrally focusing on reducing uncertainty for the decision-maker. While analysts cannot always reduce uncertainty, they should be able to accurately estimate and clearly communicate key uncertainties for decision-makers.”
“Given the importance of uncertainty in intelligence, one might expect the intelligence community to draw upon relevant science aimed at effectively handling uncertainty, much as it has done to fuel its vast collections capabilities. Yet remarkably, methods for uncertainty communication are far from having been optimized, even though the problem of uncertainty communication has resurfaced in connection with significant intelligence failures.”
We could make the same argument about the importance of accurately assessing uncertainty and emerging strategic threats in the private sector, and its association with many corporate failures. As directors, executives, and consultant, we have frequently observed the absence of best practices for communicating forecast uncertainty in private sector organizations around the world.
Mandel goes on, “Given the shortcomings of the current approach to uncertainty communication and the clear benefits of using numeric probabilities, why hasn’t effective reform happened?”
“In part, organizational inertia reflects the fact that most intelligence consumers have limited time in office, finite political capital, and crowded agendas. Efforts to tackle intelligence-community esoterica deplete resources and promise little in the way of electoral payoff. High turnover of elected officials also ensures short collective memory; practitioners can count on mistakes being forgotten without having to modify their tradecraft [i.e., analytical practices]. Even when commissions are expressly tasked with intelligence reform, they often lack the requisite knowledge base, resulting in superficial solutions.”
“Beyond these institutional barriers, intelligence producers and consumers alike may view it in their best interests to sacrifice epistemic quality in intelligence to better serve other pragmatic goals.”
“For forecast consumers, linguistic probabilities provide wiggle room to interpret intelligence estimates in ways that align with their policy preconceptions and preferences—and if things go wrong, they have the intelligence community to blame for its lack of clarity. Historically, intelligence consumers have exploited imprecision to justify decisions and deflect blame when they produced negative outcomes.”
Unfortunately, that’s equally true in the private sector.
(Source: “Uncertainty, Intelligence, and National Security Decision Making”, by David Mandel and Daniel Irwin).
However, it’s not just forecast consumers who are to blame for the current state of affairs. As Mandel notes, “Given that there is far more to lose by overconfidently asserting claims that prove to be false than by underconfidently making claims that prove to be true, intelligence organizations are likely motivated to make timid forecasts that water down information value to decision-makers—a play-it-safe strategy that anticipates unwelcome entry into the political blame games that punctuate history.”
(Source: “Intelligence, Science and the Ignorance Hypothesis”, by David Mandel)
Conclusion
As we noted at the outset, even before the COVID pandemic arrived the world had entered a period of unprecedented or radical uncertainty and disruptive change.
In this environment, avoiding failure in part depends on effectively meeting three forecasting challenges:
• Asking the right forecasting questions;
• Accurately estimating their possible outcomes; and
• Effectively communicating the degree and nature of the uncertainty associated with your forecast.
Meeting these challenges has proven to be difficult in the world of professional intelligence analysis; this is even more so the case in the private sector, as the history of corporate failure painfully shows.
Of these three challenges, effectively communicating the degree and nature of the uncertainty associated with forecasts has received the least attention.
Fortunately, David Mandel has made it his focus. His research is too little known and appreciated outside the intelligence community (and even within it, unfortunately).
By briefly summarizing his research here, we hope Mandel’s work can help far more organizations to improve their forecasting practices and substantially improve their chances of avoiding failure and achieving their goals.
Britten Coyne Partners advises clients how to establish methods, processes, structures, and systems that enable them to better anticipate, accurately assess, and adapt in time to emerging threats and avoid strategic failures. Through our affiliate, The Strategic Risk Institute, we also provide online and in-person courses leading to a Certificate in Strategic Risk Governance and Management.